 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Improvement for Capsule Networks using Depthwise Separable Convolution
Paper and Code
Jul 30, 2020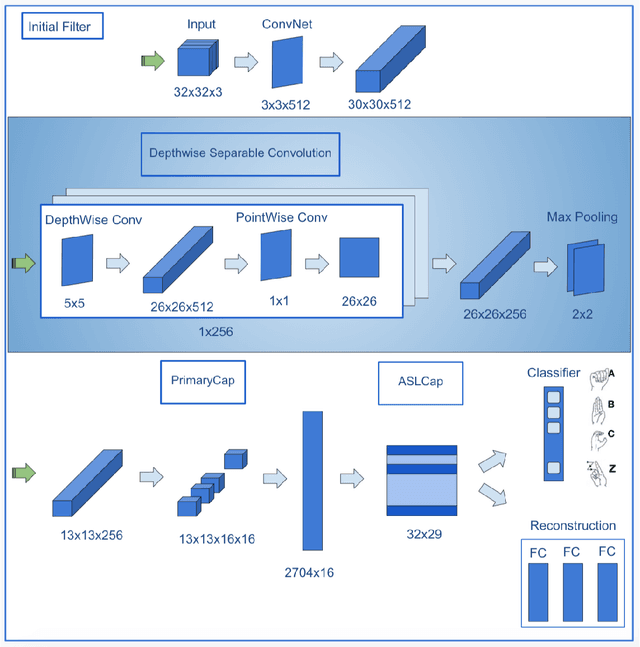
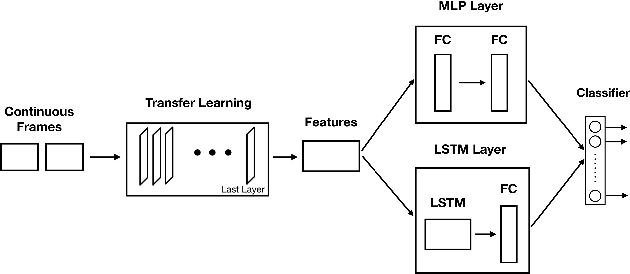
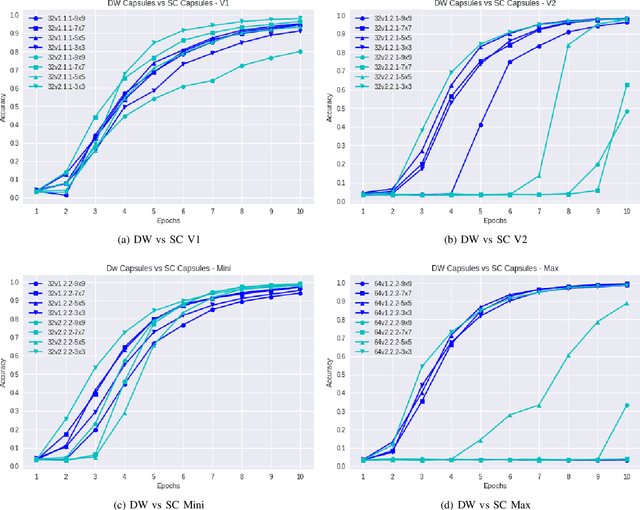
Capsule Networks face a critical problem in computer vision in the sense that the image background can challenge its performance, although they learn very well on training data. In this work, we propose to improve Capsule Networks' architecture by replacing the Standard Convolution with a Depthwise Separable Convolution. This new design significantly reduces the model's total parameters while increases stability and offers competitive accuracy. In addition, the proposed model on $64\times64$ pixel images outperforms standard models on $32\times32$ and $64\times64$ pixel images. Moreover, we empirically evaluate these models with Deep Learning architectures using state-of-the-art Transfer Learning networks such as Inception V3 and MobileNet V1. The results show that Capsule Networks perform equivalently against Deep Learning models. To the best of our knowledge, we believe that this is the first work on the integration of Depthwise Separable Convolution into Capsule Networks.