 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Frame Extraction: A Novel Approach Through Frame Similarity and Surgical Tool Tracking for Video Segmentation
Jan 19, 2025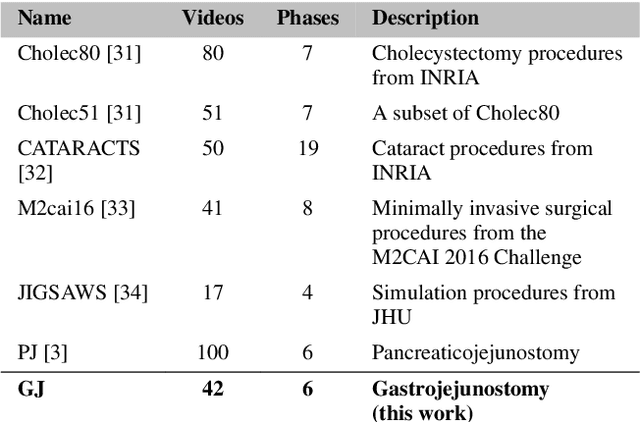
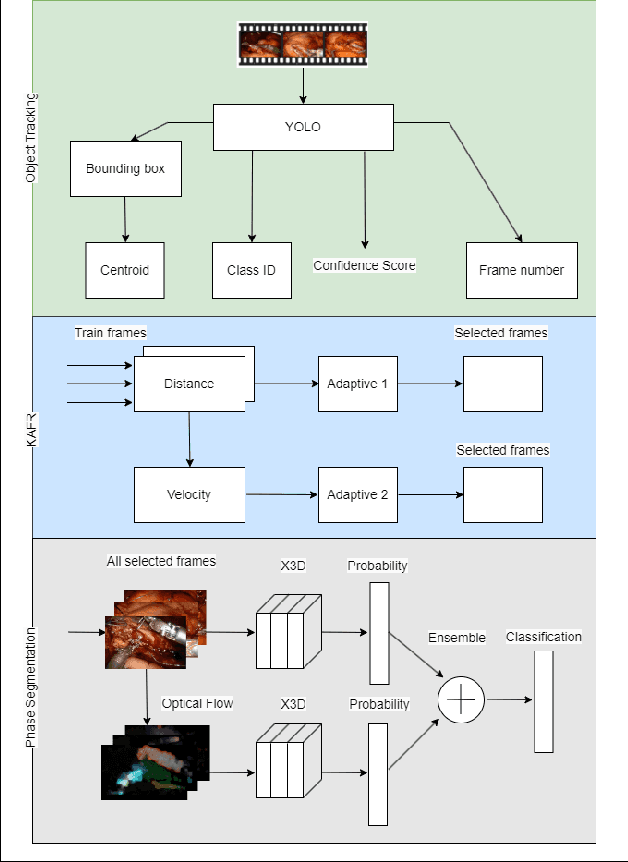
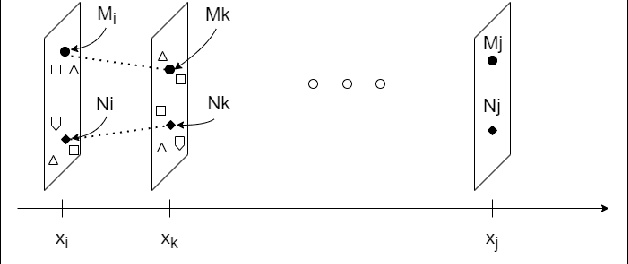

The interest in leveraging Artificial Intelligence (AI) for surgical procedures to automate analysis has witnessed a significant surge in recent years. One of the primary tools for recording surgical procedures and conducting subsequent analyses, such as performance assessment, is through videos. However, these operative videos tend to be notably lengthy compared to other fields, spanning from thirty minutes to several hours, which poses a challenge for AI models to effectively learn from them. Despite this challenge, the foreseeable increase in the volume of such videos in the near future necessitates the development and implementation of innovative techniques to tackle this issue effectively. In this article, we propose a novel technique called Kinematics Adaptive Frame Recognition (KAFR) that can efficiently eliminate redundant frames to reduce dataset size and computation time while retaining useful frames to improve accuracy. Specifically, we compute the similarity between consecutive frames by tracking the movement of surgical tools. Our approach follows these steps: i) Tracking phase: a YOLOv8 model is utilized to detect tools presented in the scene, ii) Similarity phase: Similarities between consecutive frames are computed by estimating variation in the spatial positions and velocities of the tools, iii) Classification phase: A X3D CNN is trained to classify segmentation. We evaluate the effectiveness of our approach by analyzing datasets obtained through retrospective reviews of cases at two referral centers. The Gastrojejunostomy (GJ) dataset covers procedures performed between 2017 to 2021, while the Pancreaticojejunostomy (PJ) dataset spans from 2011 to 2022 at the same centers. By adaptively selecting relevant frames, we achieve a tenfold reduction in the number of frames while improving accuracy by 4.32% (from 0.749 to 0.7814).
Evaluating Model Performance with Hard-Swish Activation Function Adjustments
Oct 09, 2024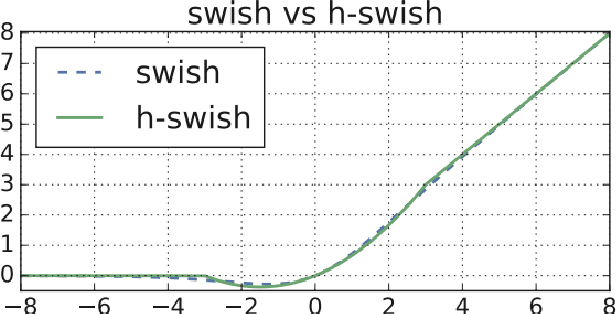



In the field of pattern recognition, achieving high accuracy is essential. While training a model to recognize different complex images, it is vital to fine-tune the model to achieve the highest accuracy possible. One strategy for fine-tuning a model involves changing its activation function. Most pre-trained models use ReLU as their default activation function, but switching to a different activation function like Hard-Swish could be beneficial. This study evaluates the performance of models using ReLU, Swish and Hard-Swish activation functions across diverse image datasets. Our results show a 2.06% increase in accuracy for models on the CIFAR-10 dataset and a 0.30% increase in accuracy for models on the ATLAS dataset. Modifying the activation functions in architecture of pre-trained models lead to improved overall accuracy.
* 2 pages