 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Frame Extraction: A Novel Approach Through Frame Similarity and Surgical Tool Tracking for Video Segmentation
Jan 19, 2025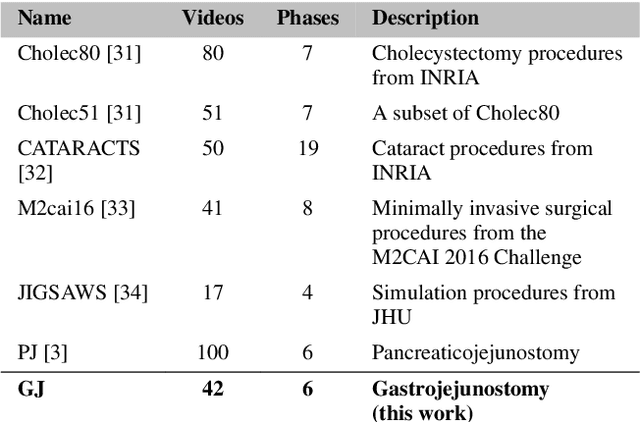
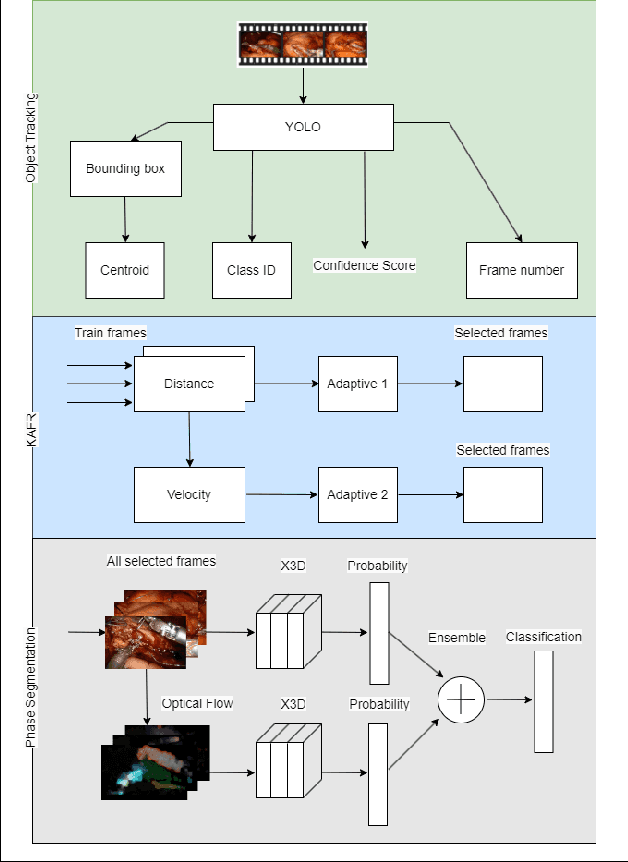

The interest in leveraging Artificial Intelligence (AI) for surgical procedures to automate analysis has witnessed a significant surge in recent years. One of the primary tools for recording surgical procedures and conducting subsequent analyses, such as performance assessment, is through videos. However, these operative videos tend to be notably lengthy compared to other fields, spanning from thirty minutes to several hours, which poses a challenge for AI models to effectively learn from them. Despite this challenge, the foreseeable increase in the volume of such videos in the near future necessitates the development and implementation of innovative techniques to tackle this issue effectively. In this article, we propose a novel technique called Kinematics Adaptive Frame Recognition (KAFR) that can efficiently eliminate redundant frames to reduce dataset size and computation time while retaining useful frames to improve accuracy. Specifically, we compute the similarity between consecutive frames by tracking the movement of surgical tools. Our approach follows these steps: i) Tracking phase: a YOLOv8 model is utilized to detect tools presented in the scene, ii) Similarity phase: Similarities between consecutive frames are computed by estimating variation in the spatial positions and velocities of the tools, iii) Classification phase: A X3D CNN is trained to classify segmentation. We evaluate the effectiveness of our approach by analyzing datasets obtained through retrospective reviews of cases at two referral centers. The Gastrojejunostomy (GJ) dataset covers procedures performed between 2017 to 2021, while the Pancreaticojejunostomy (PJ) dataset spans from 2011 to 2022 at the same centers. By adaptively selecting relevant frames, we achieve a tenfold reduction in the number of frames while improving accuracy by 4.32% (from 0.749 to 0.7814).
Machine Learning-Based Automated Assessment of Intracorporeal Suturing in Laparoscopic Fundoplication
Dec 16, 2024



Automated assessment of surgical skills using artificial intelligence (AI) provides trainees with instantaneous feedback. After bimanual tool motions are captured, derived kinematic metrics are reliable predictors of performance in laparoscopic tasks. Implementing automated tool tracking requires time-intensive human annotation. We developed AI-based tool tracking using the Segment Anything Model (SAM) to eliminate the need for human annotators. Here, we describe a study evaluating the usefulness of our tool tracking model in automated assessment during a laparoscopic suturing task in the fundoplication procedure. An automated tool tracking model was applied to recorded videos of Nissen fundoplication on porcine bowel. Surgeons were grouped as novices (PGY1-2) and experts (PGY3-5, attendings). The beginning and end of each suturing step were segmented, and motions of the left and right tools were extracted. A low-pass filter with a 24 Hz cut-off frequency removed noise. Performance was assessed using supervised and unsupervised models, and an ablation study compared results. Kinematic features--RMS velocity, RMS acceleration, RMS jerk, total path length, and Bimanual Dexterity--were extracted and analyzed using Logistic Regression, Random Forest, Support Vector Classifier, and XGBoost. PCA was performed for feature reduction. For unsupervised learning, a Denoising Autoencoder (DAE) model with classifiers, such as a 1-D CNN and traditional models, was trained. Data were extracted for 28 participants (9 novices, 19 experts). Supervised learning with PCA and Random Forest achieved an accuracy of 0.795 and an F1 score of 0.778. The unsupervised 1-D CNN achieved superior results with an accuracy of 0.817 and an F1 score of 0.806, eliminating the need for kinematic feature computation. We demonstrated an AI model capable of automated performance classification, independent of human annotation.
Evaluating Model Performance with Hard-Swish Activation Function Adjustments
Oct 09, 2024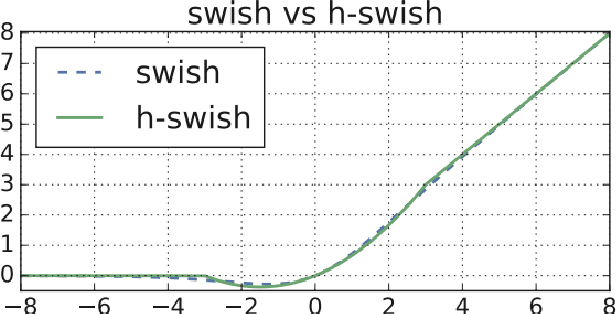



In the field of pattern recognition, achieving high accuracy is essential. While training a model to recognize different complex images, it is vital to fine-tune the model to achieve the highest accuracy possible. One strategy for fine-tuning a model involves changing its activation function. Most pre-trained models use ReLU as their default activation function, but switching to a different activation function like Hard-Swish could be beneficial. This study evaluates the performance of models using ReLU, Swish and Hard-Swish activation functions across diverse image datasets. Our results show a 2.06% increase in accuracy for models on the CIFAR-10 dataset and a 0.30% increase in accuracy for models on the ATLAS dataset. Modifying the activation functions in architecture of pre-trained models lead to improved overall accuracy.
* 2 pages
Generation and Analysis of Feature-Dependent Pseudo Noise for Training Deep Neural Networks
May 22, 2021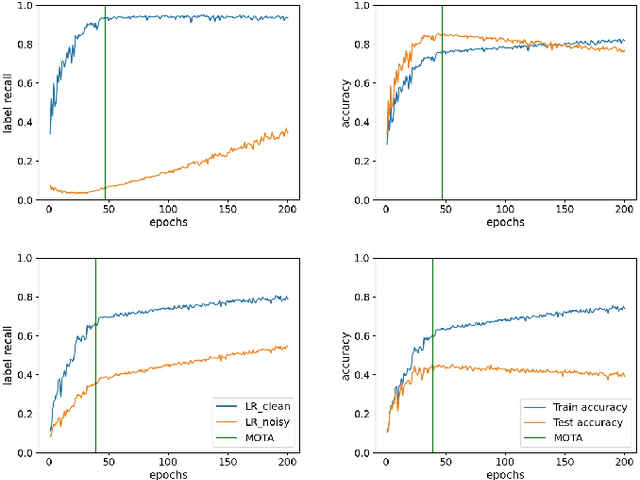
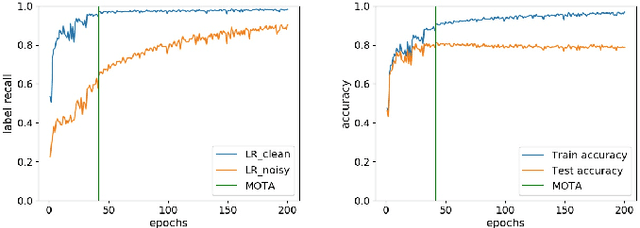
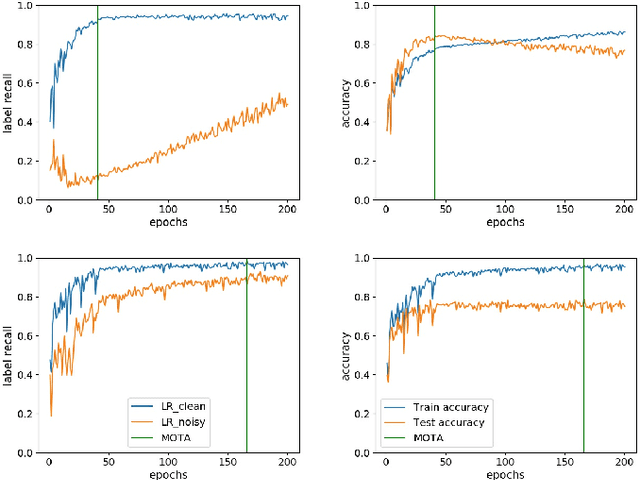
Training Deep neural networks (DNNs) on noisy labeled datasets is a challenging problem, because learning on mislabeled examples deteriorates the performance of the network. As the ground truth availability is limited with real-world noisy datasets, previous papers created synthetic noisy datasets by randomly modifying the labels of training examples of clean datasets. However, no final conclusions can be derived by just using this random noise, since it excludes feature-dependent noise. Thus, it is imperative to generate feature-dependent noisy datasets that additionally provide ground truth. Therefore, we propose an intuitive approach to creating feature-dependent noisy datasets by utilizing the training predictions of DNNs on clean datasets that also retain true label information. We refer to these datasets as "Pseudo Noisy datasets". We conduct several experiments to establish that Pseudo noisy datasets resemble feature-dependent noisy datasets across different conditions. We further randomly generate synthetic noisy datasets with the same noise distribution as that of Pseudo noise (referred as "Randomized Noise") to empirically show that i) learning is easier with feature-dependent label noise compared to random noise, ii) irrespective of noise distribution, Pseudo noisy datasets mimic feature-dependent label noise and iii) current training methods are not generalizable to feature-dependent label noise. Therefore, we believe that Pseudo noisy datasets will be quite helpful to study and develop robust training methods.
Identifying Training Stop Point with Noisy Labeled Data
Dec 24, 2020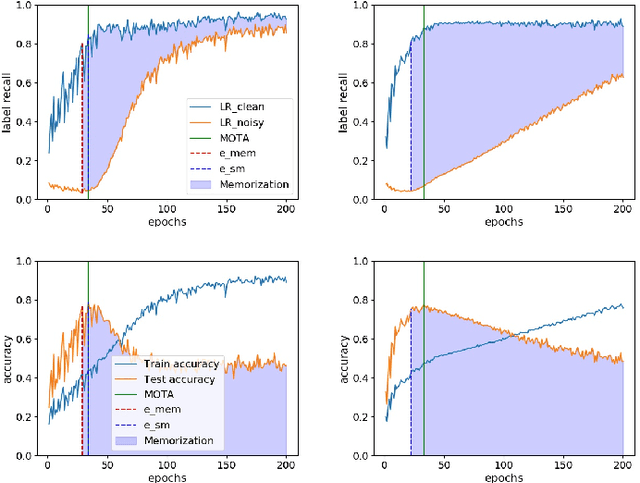
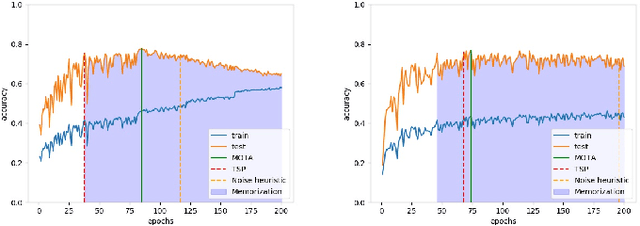
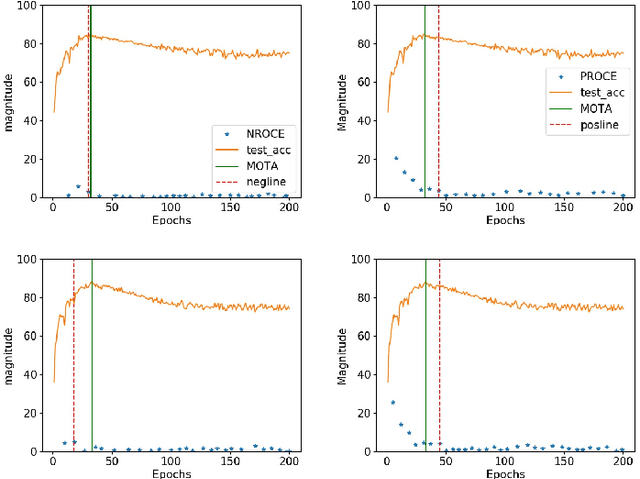
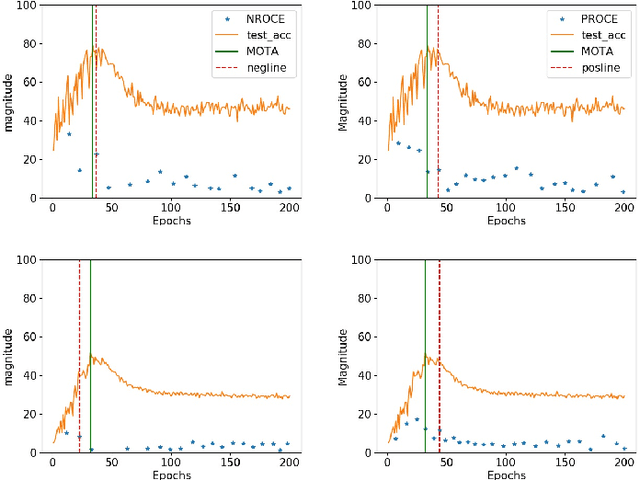
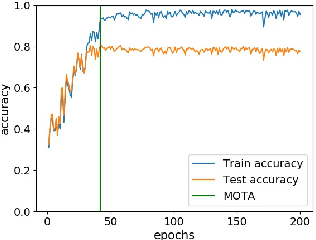
Training deep neural networks (DNNs) with noisy labels is a challenging problem due to over-parameterization. DNNs tend to essentially fit on clean samples at a higher rate in the initial stages, and later fit on the noisy samples at a relatively lower rate. Thus, with a noisy dataset, the test accuracy increases initially and drops in the later stages. To find an early stopping point at the maximum obtainable test accuracy (MOTA), recent studies assume either that i) a clean validation set is available or ii) the noise ratio is known, or, both. However, often a clean validation set is unavailable, and the noise estimation can be inaccurate. To overcome these issues, we provide a novel training solution, free of these conditions. We analyze the rate of change of the training accuracy for different noise ratios under different conditions to identify a training stop region. We further develop a heuristic algorithm based on a small-learning assumption to find a training stop point (TSP) at or close to MOTA. To the best of our knowledge, our method is the first to rely solely on the \textit{training behavior}, while utilizing the entire training set, to automatically find a TSP. We validated the robustness of our algorithm (AutoTSP) through several experiments on CIFAR-10, CIFAR-100, and a real-world noisy dataset for different noise ratios, noise types and architectures.
LapTool-Net: A Contextual Detector of Surgical Tools in Laparoscopic Videos Based on Recurrent Convolutional Neural Networks
May 22, 2019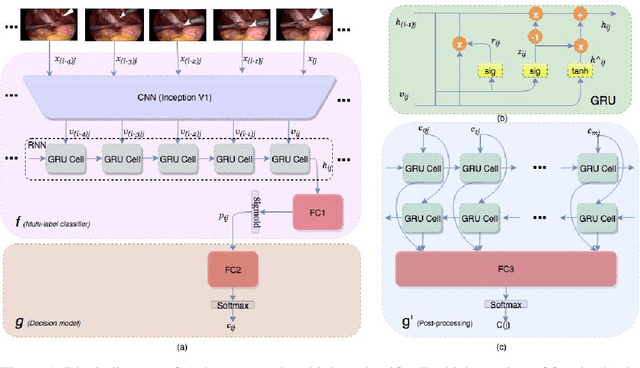
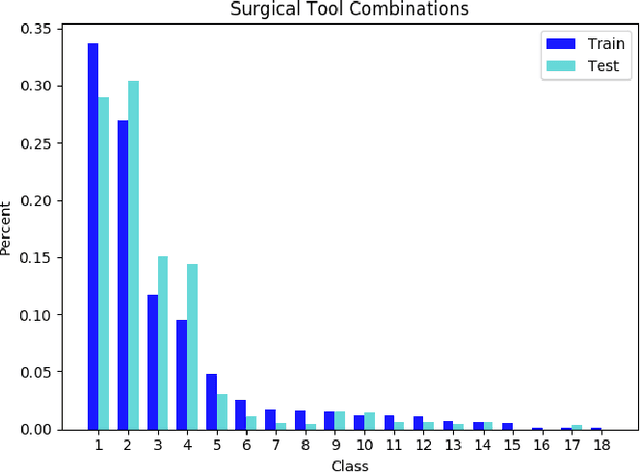
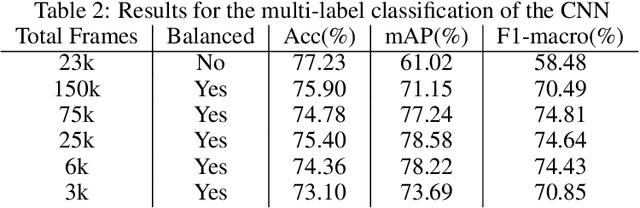
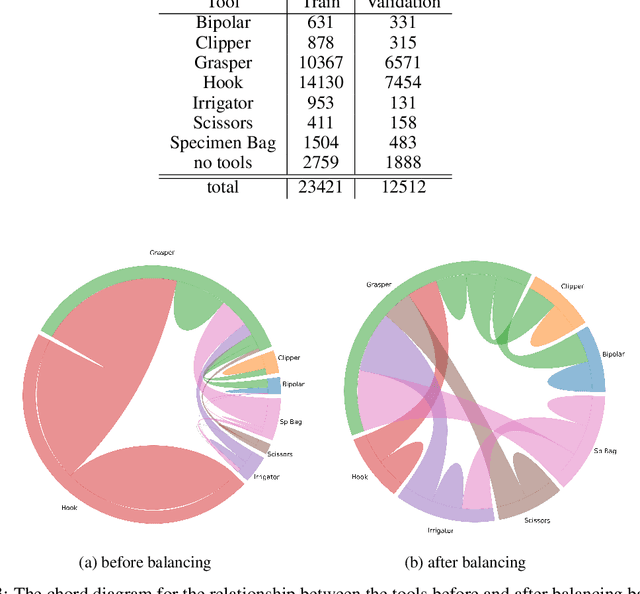
We propose a new multilabel classifier, called LapTool-Net to detect the presence of surgical tools in each frame of a laparoscopic video. The novelty of LapTool-Net is the exploitation of the correlation among the usage of different tools and, the tools and tasks - namely, the context of the tools' usage. Towards this goal, the pattern in the co-occurrence of the tools is utilized for designing a decision policy for a multilabel classifier based on a Recurrent Convolutional Neural Network (RCNN) architecture to simultaneously extract the spatio-temporal features. In contrast to the previous multilabel classification methods, the RCNN and the decision model are trained in an end-to-end manner using a multitask learning scheme. To overcome the high imbalance and avoid overfitting caused by the lack of variety in the training data, a high down-sampling rate is chosen based on the more frequent combinations. Furthermore, at the post-processing step, the prediction for all the frames of a video are corrected by designing a bi-directional RNN to model the long-term task's order. LapTool-net was trained using a publicly available dataset of laparoscopic cholecystectomy. The results show LapTool-Net outperforms existing methods significantly, even while using fewer training samples and a shallower architecture.