 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneration and Analysis of Feature-Dependent Pseudo Noise for Training Deep Neural Networks
May 22, 2021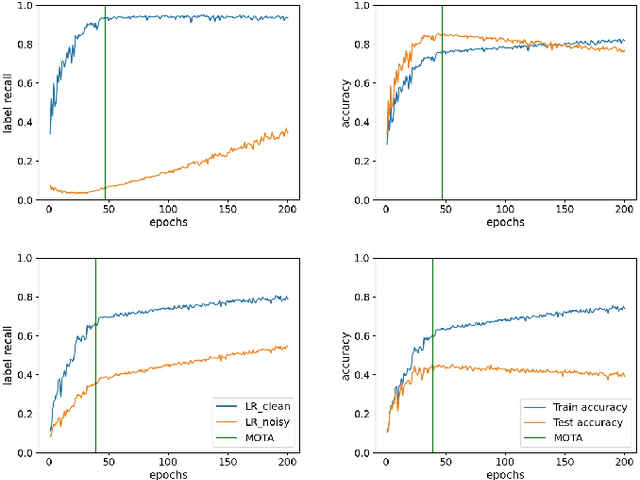
Training Deep neural networks (DNNs) on noisy labeled datasets is a challenging problem, because learning on mislabeled examples deteriorates the performance of the network. As the ground truth availability is limited with real-world noisy datasets, previous papers created synthetic noisy datasets by randomly modifying the labels of training examples of clean datasets. However, no final conclusions can be derived by just using this random noise, since it excludes feature-dependent noise. Thus, it is imperative to generate feature-dependent noisy datasets that additionally provide ground truth. Therefore, we propose an intuitive approach to creating feature-dependent noisy datasets by utilizing the training predictions of DNNs on clean datasets that also retain true label information. We refer to these datasets as "Pseudo Noisy datasets". We conduct several experiments to establish that Pseudo noisy datasets resemble feature-dependent noisy datasets across different conditions. We further randomly generate synthetic noisy datasets with the same noise distribution as that of Pseudo noise (referred as "Randomized Noise") to empirically show that i) learning is easier with feature-dependent label noise compared to random noise, ii) irrespective of noise distribution, Pseudo noisy datasets mimic feature-dependent label noise and iii) current training methods are not generalizable to feature-dependent label noise. Therefore, we believe that Pseudo noisy datasets will be quite helpful to study and develop robust training methods.
Identifying Training Stop Point with Noisy Labeled Data
Dec 24, 2020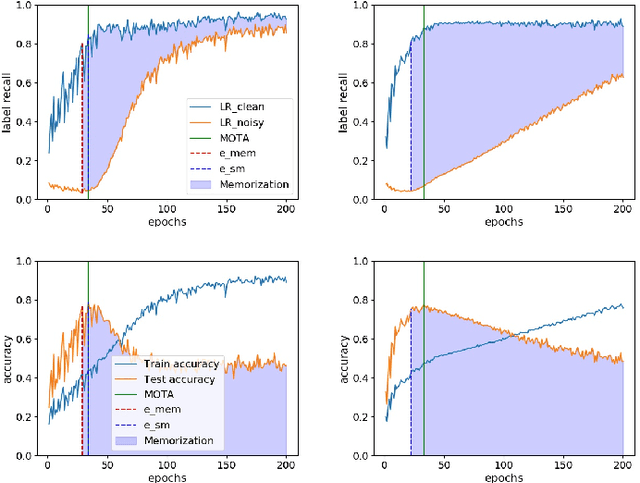
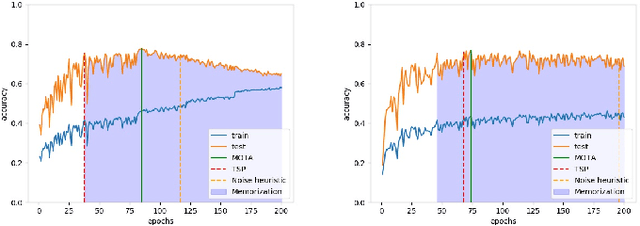
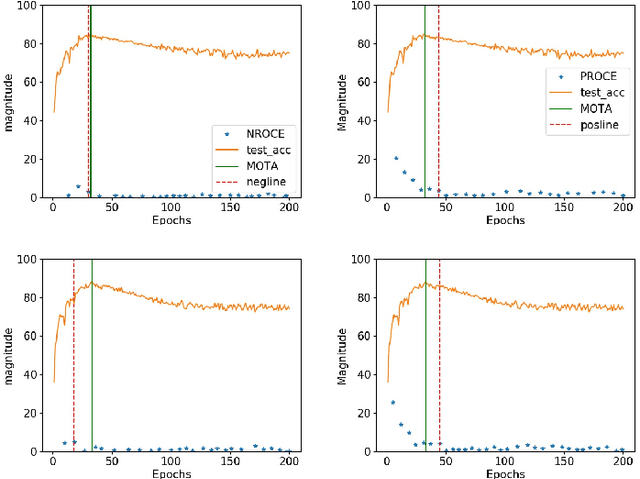
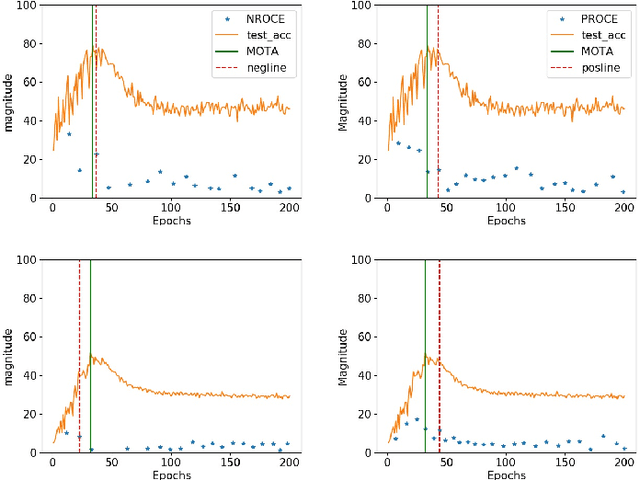
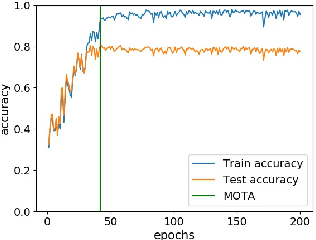
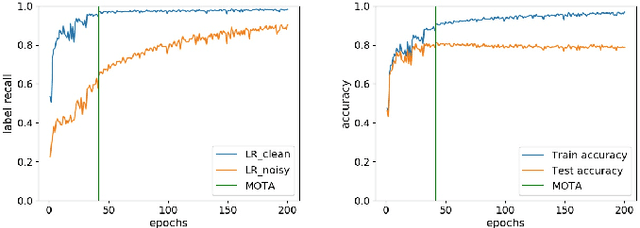
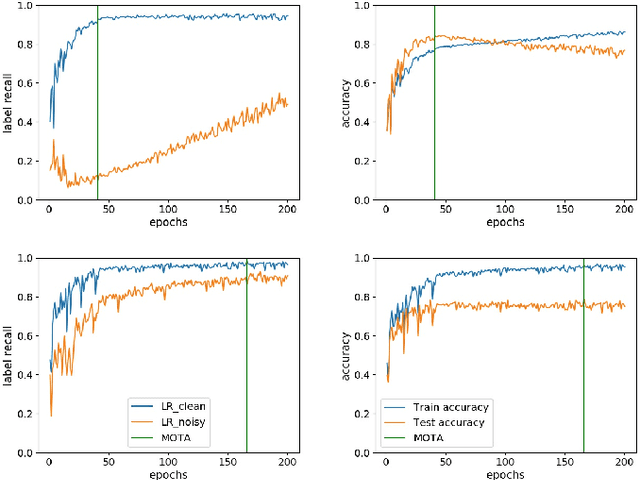
Training deep neural networks (DNNs) with noisy labels is a challenging problem due to over-parameterization. DNNs tend to essentially fit on clean samples at a higher rate in the initial stages, and later fit on the noisy samples at a relatively lower rate. Thus, with a noisy dataset, the test accuracy increases initially and drops in the later stages. To find an early stopping point at the maximum obtainable test accuracy (MOTA), recent studies assume either that i) a clean validation set is available or ii) the noise ratio is known, or, both. However, often a clean validation set is unavailable, and the noise estimation can be inaccurate. To overcome these issues, we provide a novel training solution, free of these conditions. We analyze the rate of change of the training accuracy for different noise ratios under different conditions to identify a training stop region. We further develop a heuristic algorithm based on a small-learning assumption to find a training stop point (TSP) at or close to MOTA. To the best of our knowledge, our method is the first to rely solely on the \textit{training behavior}, while utilizing the entire training set, to automatically find a TSP. We validated the robustness of our algorithm (AutoTSP) through several experiments on CIFAR-10, CIFAR-100, and a real-world noisy dataset for different noise ratios, noise types and architectures.
LapTool-Net: A Contextual Detector of Surgical Tools in Laparoscopic Videos Based on Recurrent Convolutional Neural Networks
May 22, 2019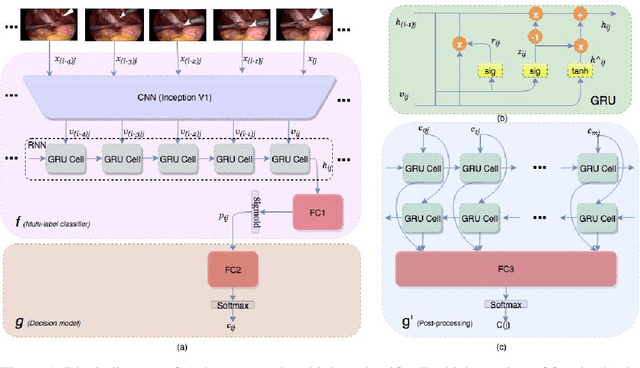
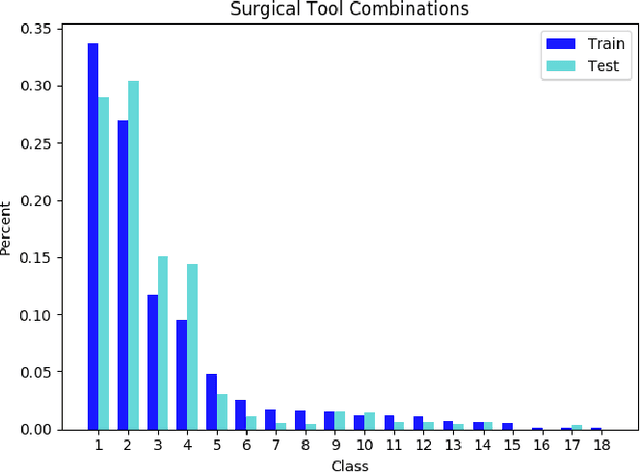
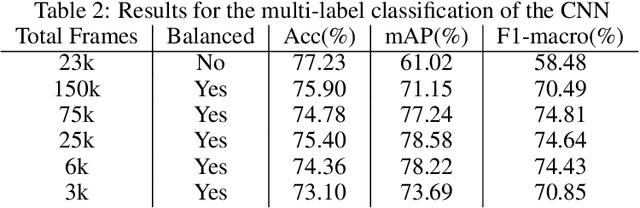
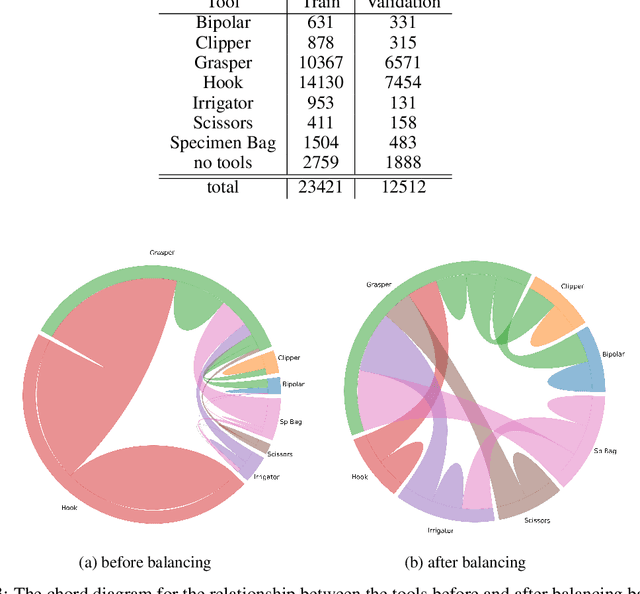
We propose a new multilabel classifier, called LapTool-Net to detect the presence of surgical tools in each frame of a laparoscopic video. The novelty of LapTool-Net is the exploitation of the correlation among the usage of different tools and, the tools and tasks - namely, the context of the tools' usage. Towards this goal, the pattern in the co-occurrence of the tools is utilized for designing a decision policy for a multilabel classifier based on a Recurrent Convolutional Neural Network (RCNN) architecture to simultaneously extract the spatio-temporal features. In contrast to the previous multilabel classification methods, the RCNN and the decision model are trained in an end-to-end manner using a multitask learning scheme. To overcome the high imbalance and avoid overfitting caused by the lack of variety in the training data, a high down-sampling rate is chosen based on the more frequent combinations. Furthermore, at the post-processing step, the prediction for all the frames of a video are corrected by designing a bi-directional RNN to model the long-term task's order. LapTool-net was trained using a publicly available dataset of laparoscopic cholecystectomy. The results show LapTool-Net outperforms existing methods significantly, even while using fewer training samples and a shallower architecture.