 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTalTech-IRIT-LIS Speaker and Language Diarization Systems for DISPLACE 2024
Jul 17, 2024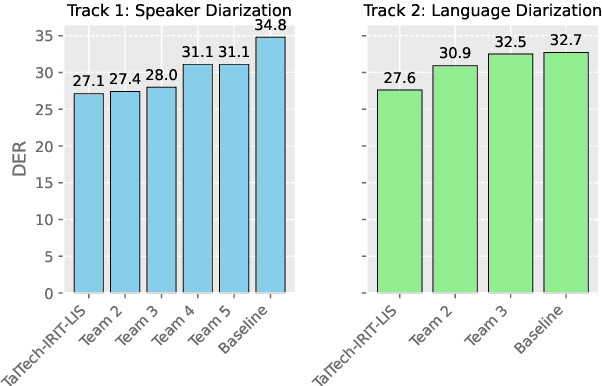
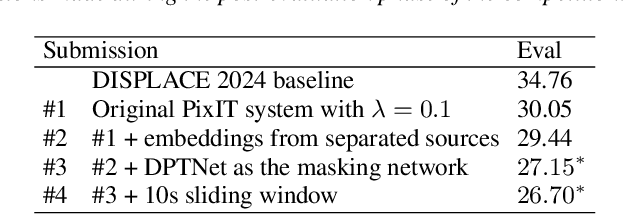


This paper describes the submissions of team TalTech-IRIT-LIS to the DISPLACE 2024 challenge. Our team participated in the speaker diarization and language diarization tracks of the challenge. In the speaker diarization track, our best submission was an ensemble of systems based on the pyannote.audio speaker diarization pipeline utilizing powerset training and our recently proposed PixIT method that performs joint diarization and speech separation. We improve upon PixIT by using the separation outputs for speaker embedding extraction. Our ensemble achieved a diarization error rate of 27.1% on the evaluation dataset. In the language diarization track, we fine-tuned a pre-trained Wav2Vec2-BERT language embedding model on in-domain data, and clustered short segments using AHC and VBx, based on similarity scores from LDA/PLDA. This led to a language diarization error rate of 27.6% on the evaluation data. Both results were ranked first in their respective challenge tracks.
Explainable by-design Audio Segmentation through Non-Negative Matrix Factorization and Probing
Jun 19, 2024
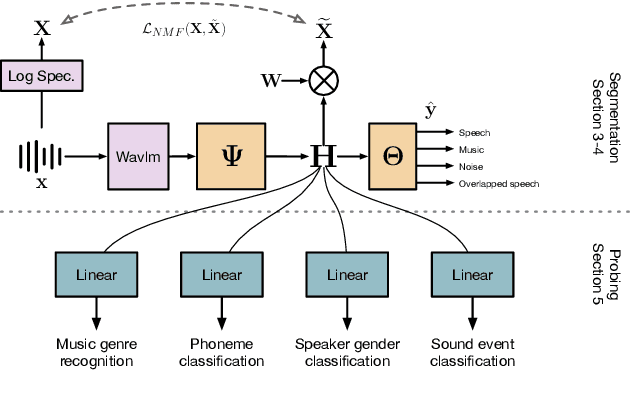
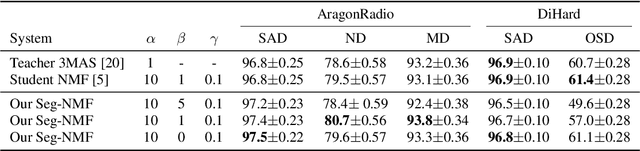
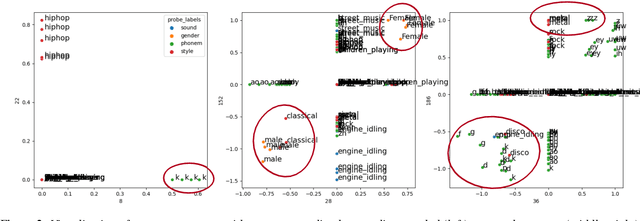
Audio segmentation is a key task for many speech technologies, most of which are based on neural networks, usually considered as black boxes, with high-level performances. However, in many domains, among which health or forensics, there is not only a need for good performance but also for explanations about the output decision. Explanations derived directly from latent representations need to satisfy "good" properties, such as informativeness, compactness, or modularity, to be interpretable. In this article, we propose an explainable-by-design audio segmentation model based on non-negative matrix factorization (NMF) which is a good candidate for the design of interpretable representations. This paper shows that our model reaches good segmentation performances, and presents deep analyses of the latent representation extracted from the non-negative matrix. The proposed approach opens new perspectives toward the evaluation of interpretable representations according to "good" properties.
Joint speech and overlap detection: a benchmark over multiple audio setup and speech domains
Jul 24, 2023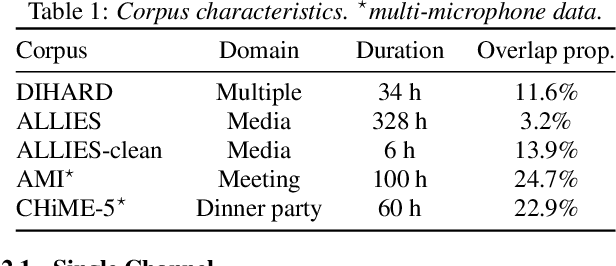
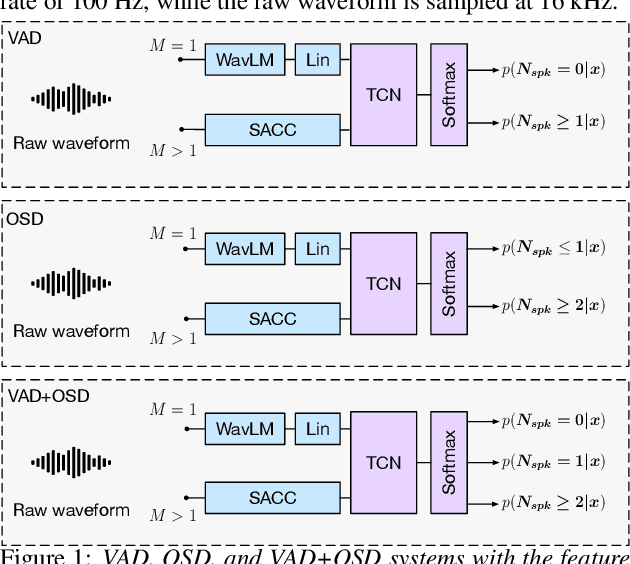

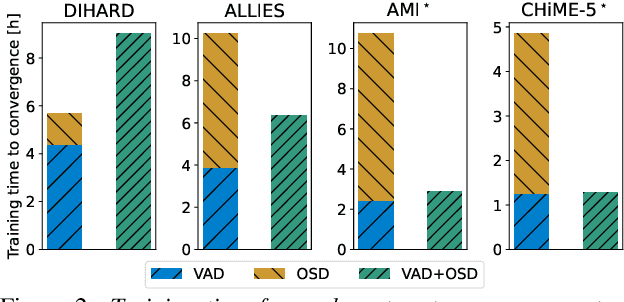
Voice activity and overlapped speech detection (respectively VAD and OSD) are key pre-processing tasks for speaker diarization. The final segmentation performance highly relies on the robustness of these sub-tasks. Recent studies have shown VAD and OSD can be trained jointly using a multi-class classification model. However, these works are often restricted to a specific speech domain, lacking information about the generalization capacities of the systems. This paper proposes a complete and new benchmark of different VAD and OSD models, on multiple audio setups (single/multi-channel) and speech domains (e.g. media, meeting...). Our 2/3-class systems, which combine a Temporal Convolutional Network with speech representations adapted to the setup, outperform state-of-the-art results. We show that the joint training of these two tasks offers similar performances in terms of F1-score to two dedicated VAD and OSD systems while reducing the training cost. This unique architecture can also be used for single and multichannel speech processing.
Overlapped speech and gender detection with WavLM pre-trained features
Sep 09, 2022
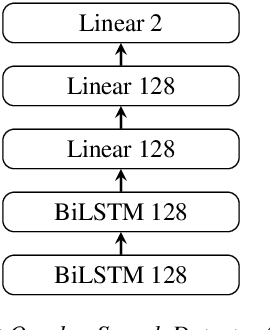

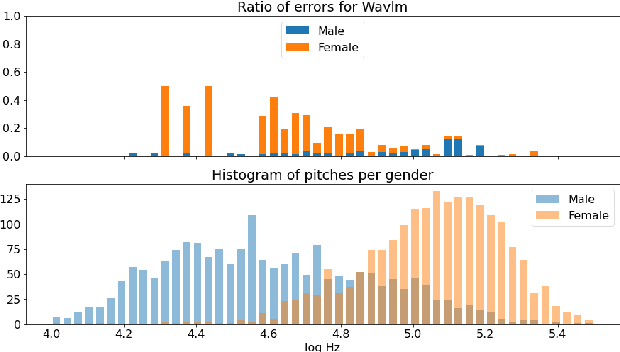
This article focuses on overlapped speech and gender detection in order to study interactions between women and men in French audiovisual media (Gender Equality Monitoring project). In this application context, we need to automatically segment the speech signal according to speakers gender, and to identify when at least two speakers speak at the same time. We propose to use WavLM model which has the advantage of being pre-trained on a huge amount of speech data, to build an overlapped speech detection (OSD) and a gender detection (GD) systems. In this study, we use two different corpora. The DIHARD III corpus which is well adapted for the OSD task but lack gender information. The ALLIES corpus fits with the project application context. Our best OSD system is a Temporal Convolutional Network (TCN) with WavLM pre-trained features as input, which reaches a new state-of-the-art F1-score performance on DIHARD. A neural GD is trained with WavLM inputs on a gender balanced subset of the French broadcast news ALLIES data, and obtains an accuracy of 97.9%. This work opens new perspectives for human science researchers regarding the differences of representation between women and men in French media.