 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePretraining Approaches for Spoken Language Recognition: TalTech Submission to the OLR 2021 Challenge
May 14, 2022
This paper investigates different pretraining approaches to spoken language identification. The paper is based on our submission to the Oriental Language Recognition 2021 Challenge. We participated in two tracks of the challenge: constrained and unconstrained language recognition. For the constrained track, we first trained a Conformer-based encoder-decoder model for multilingual automatic speech recognition (ASR), using the provided training data that had transcripts available. The shared encoder of the multilingual ASR model was then finetuned for the language identification task. For the unconstrained task, we relied on both externally available pretrained models as well as external data: the multilingual XLSR-53 wav2vec2.0 model was finetuned on the VoxLingua107 corpus for the language recognition task, and finally finetuned on the provided target language training data, augmented with CommonVoice data. Our primary metric $C_{\rm avg}$ values on the Test set are 0.0079 for the constrained task and 0.0119 for the unconstrained task which resulted in the second place in both rankings. In post-evaluation experiments, we study the amount of target language data needed for training an accurate backend model, the importance of multilingual pretraining data, and compare different models as finetuning starting points.
Improving Language Identification of Accented Speech
Apr 01, 2022
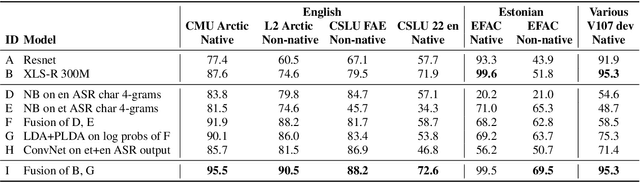
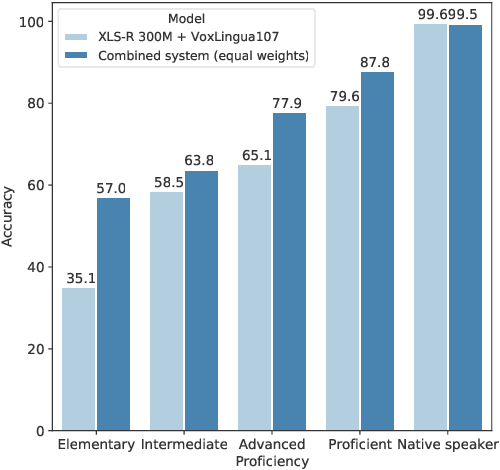
Language identification from speech is a common preprocessing step in many spoken language processing systems. In recent years, this field has seen a fast progress, mostly due to the use of self-supervised models pretrained on multilingual data and the use of large training corpora. This paper shows that for speech with a non-native or regional accent, the accuracy of spoken language identification systems drops dramatically, and that the accuracy of identifying the language is inversely correlated with the strength of the accent. We also show that using the output of a lexicon-free speech recognition system of the particular language helps to improve language identification performance on accented speech by a large margin, without sacrificing accuracy on native speech. We obtain relative error rate reductions ranging from to 35 to 63% over the state-of-the-art model across several non-native speech datasets.