 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdvanced Rich Transcription System for Estonian Speech
Jan 11, 2019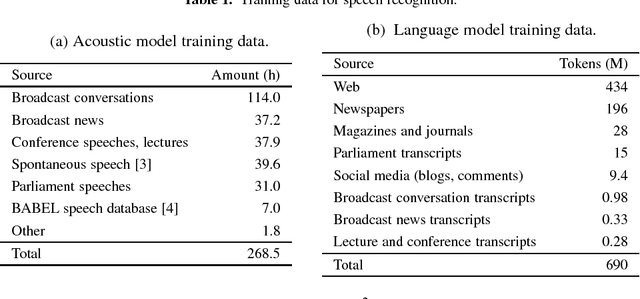
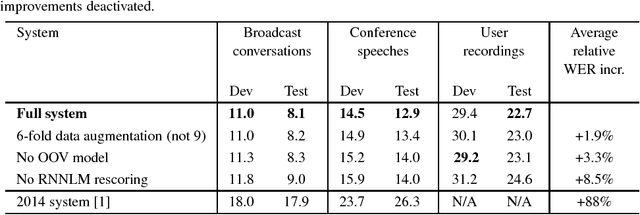

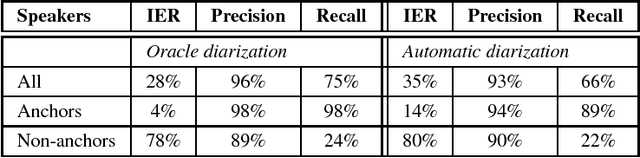
This paper describes the current TT\"U speech transcription system for Estonian speech. The system is designed to handle semi-spontaneous speech, such as broadcast conversations, lecture recordings and interviews recorded in diverse acoustic conditions. The system is based on the Kaldi toolkit. Multi-condition training using background noise profiles extracted automatically from untranscribed data is used to improve the robustness of the system. Out-of-vocabulary words are recovered using a phoneme n-gram based decoding subgraph and a FST-based phoneme-to-grapheme model. The system achieves a word error rate of 8.1% on a test set of broadcast conversations. The system also performs punctuation recovery and speaker identification. Speaker identification models are trained using a recently proposed weakly supervised training method.
* Published in Baltic HLT 2018 (putting it on arXiv because Google Scholar doesn't index it properly)