 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSiamese BERT-based Model for Web Search Relevance Ranking Evaluated on a New Czech Dataset
Paper and Code



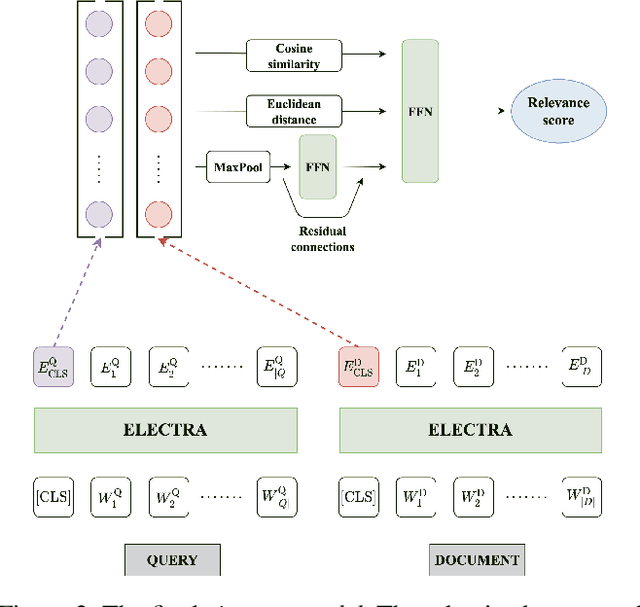
Web search engines focus on serving highly relevant results within hundreds of milliseconds. Pre-trained language transformer models such as BERT are therefore hard to use in this scenario due to their high computational demands. We present our real-time approach to the document ranking problem leveraging a BERT-based siamese architecture. The model is already deployed in a commercial search engine and it improves production performance by more than 3%. For further research and evaluation, we release DaReCzech, a unique data set of 1.6 million Czech user query-document pairs with manually assigned relevance levels. We also release Small-E-Czech, an Electra-small language model pre-trained on a large Czech corpus. We believe this data will support endeavours both of search relevance and multilingual-focused research communities.