 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSome Like It Small: Czech Semantic Embedding Models for Industry Applications
Nov 23, 2023This article focuses on the development and evaluation of Small-sized Czech sentence embedding models. Small models are important components for real-time industry applications in resource-constrained environments. Given the limited availability of labeled Czech data, alternative approaches, including pre-training, knowledge distillation, and unsupervised contrastive fine-tuning, are investigated. Comprehensive intrinsic and extrinsic analyses are conducted, showcasing the competitive performance of our models compared to significantly larger counterparts, with approximately 8 times smaller size and 5 times faster speed than conventional Base-sized models. To promote cooperation and reproducibility, both the models and the evaluation pipeline are made publicly accessible. Ultimately, this article presents practical applications of the developed sentence embedding models in Seznam.cz, the Czech search engine. These models have effectively replaced previous counterparts, enhancing the overall search experience for instance, in organic search, featured snippets, and image search. This transition has yielded improved performance.
COSTRA 1.0: A Dataset of Complex Sentence Transformations
Dec 03, 2019
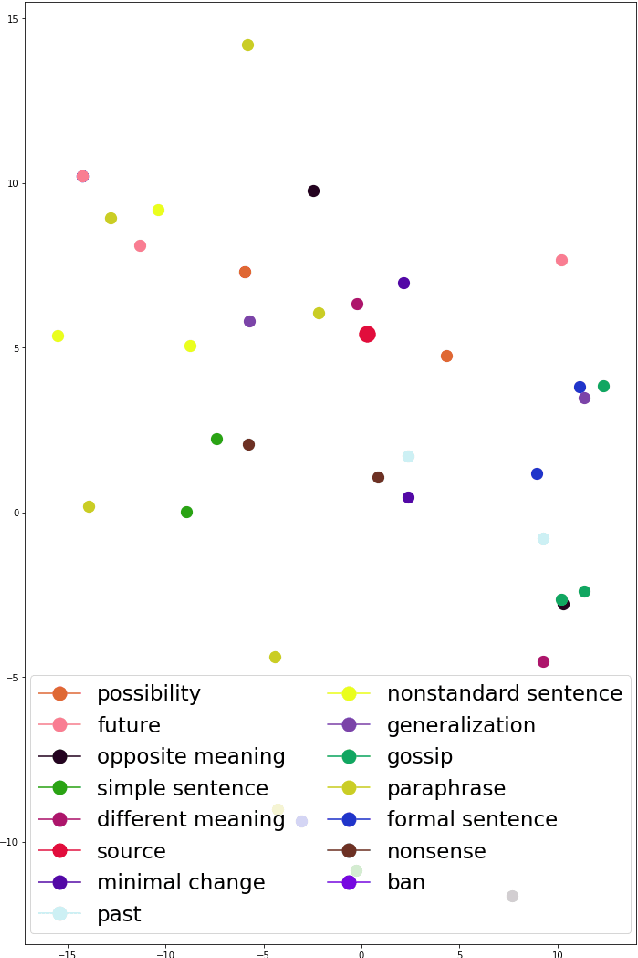


We present COSTRA 1.0, a dataset of complex sentence transformations. The dataset is intended for the study of sentence-level embeddings beyond simple word alternations or standard paraphrasing. This first version of the dataset is limited to sentences in Czech but the construction method is universal and we plan to use it also for other languages. The dataset consist of 4,262 unique sentences with average length of 10 words, illustrating 15 types of modifications such as simplification, generalization, or formal and informal language variation. The hope is that with this dataset, we should be able to test semantic properties of sentence embeddings and perhaps even to find some topologically interesting 'skeleton' in the sentence embedding space. A preliminary analysis using LASER, multi-purpose multi-lingual sentence embeddings suggests that the LASER space does not exhibit the desired properties.
In Search for Linear Relations in Sentence Embedding Spaces
Oct 08, 2019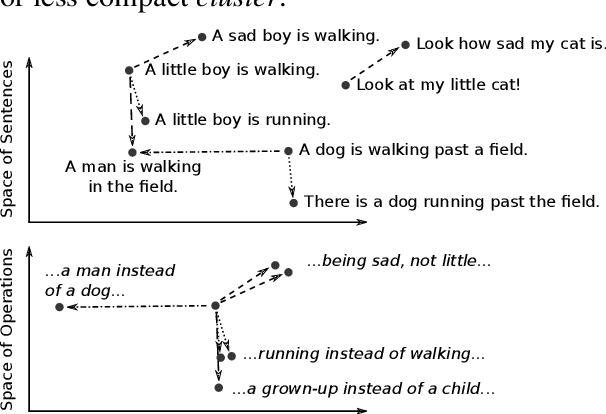
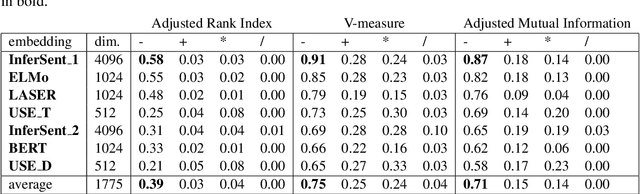

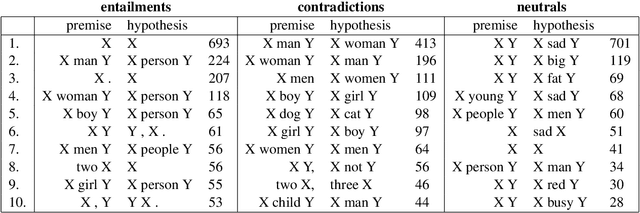
We present an introductory investigation into continuous-space vector representations of sentences. We acquire pairs of very similar sentences differing only by a small alterations (such as change of a noun, adding an adjective, noun or punctuation) from datasets for natural language inference using a simple pattern method. We look into how such a small change within the sentence text affects its representation in the continuous space and how such alterations are reflected by some of the popular sentence embedding models. We found that vector differences of some embeddings actually reflect small changes within a sentence.