 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCOSTRA 1.0: A Dataset of Complex Sentence Transformations
Paper and Code
Dec 03, 2019
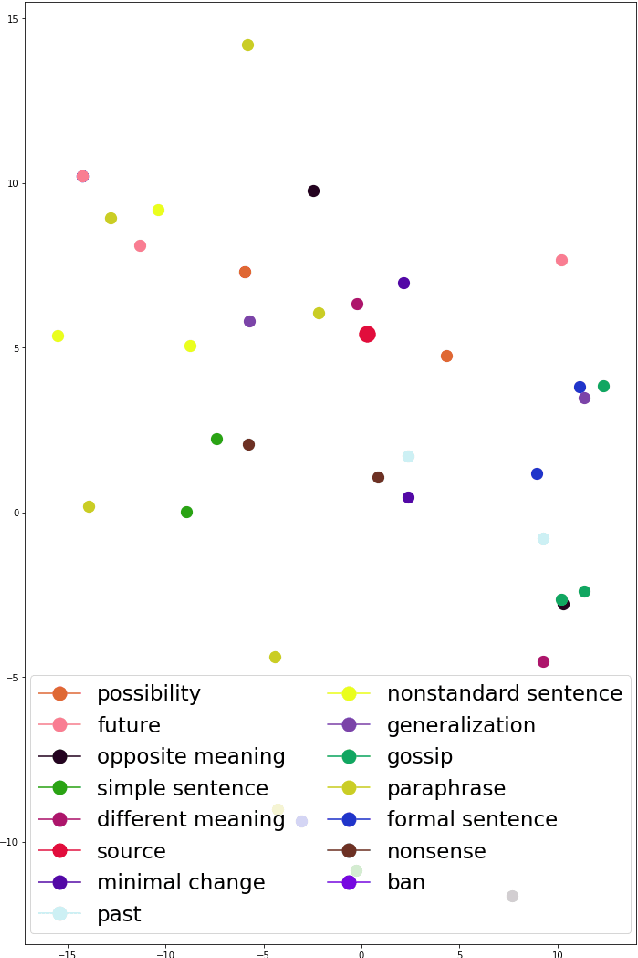


We present COSTRA 1.0, a dataset of complex sentence transformations. The dataset is intended for the study of sentence-level embeddings beyond simple word alternations or standard paraphrasing. This first version of the dataset is limited to sentences in Czech but the construction method is universal and we plan to use it also for other languages. The dataset consist of 4,262 unique sentences with average length of 10 words, illustrating 15 types of modifications such as simplification, generalization, or formal and informal language variation. The hope is that with this dataset, we should be able to test semantic properties of sentence embeddings and perhaps even to find some topologically interesting 'skeleton' in the sentence embedding space. A preliminary analysis using LASER, multi-purpose multi-lingual sentence embeddings suggests that the LASER space does not exhibit the desired properties.