 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding Model Robustness to User-generated Noisy Texts
Paper and Code
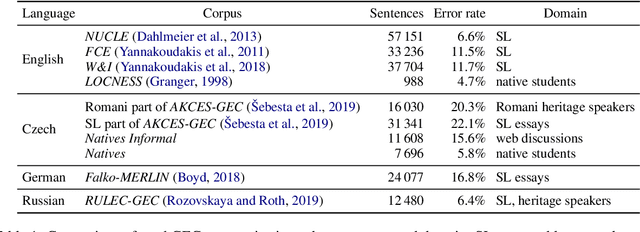

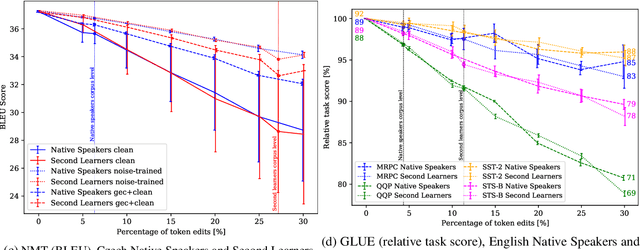
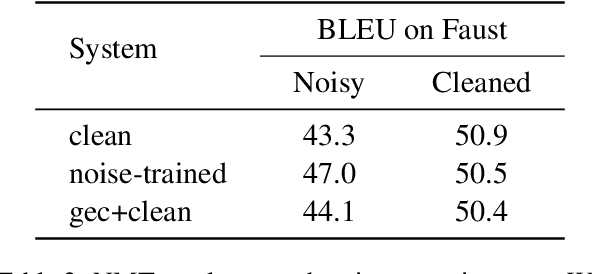
Sensitivity of deep-neural models to input noise is known to be a challenging problem. In NLP, model performance often deteriorates with naturally occurring noise, such as spelling errors. To mitigate this issue, models may leverage artificially noised data. However, the amount and type of generated noise has so far been determined arbitrarily. We therefore propose to model the errors statistically from grammatical-error-correction corpora. We present a thorough evaluation of several state-of-the-art NLP systems' robustness in multiple languages, with tasks including morpho-syntactic analysis, named entity recognition, neural machine translation, a subset of the GLUE benchmark and reading comprehension. We also compare two approaches to address the performance drop: a) training the NLP models with noised data generated by our framework; and b) reducing the input noise with external system for natural language correction. The code is released at https://github.com/ufal/kazitext.