 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptical Music Recognition for Real-World Manuscripts with Synthetic Data
Jun 08, 2026Optical Music Recognition (OMR) has seen major progress in model design, with end-to-end methods now capable of recognising notation at all levels of complexity. However, the impact of this progress has been limited by the visual domains of available training datasets, which are largely born-digital. Existing large collections of sheet music in libraries and other heritage institutions contain predominantly manuscripts, whose visual domains are highly diverse and different, so existing OMR systems fail when applied in the real world. These institutions are often resource-constrained, so large in-domain datasets cannot be expected. We provide a first baseline on real-world manuscripts with complex piano notation in the resource-constrained scenario. Using fine-grained music notation graph (MuNG) annotations and the Smashcima synthesis tool, we then show that while some direct transcriptions of in-domain data remain essential, domain adaptation using synthetic musical manuscript images brings significant improvement. Furthermore, the symbols used do not need to be in-domain, so the expensive fine-grained annotation can be avoided. We thus bring OMR closer to one of its stated goals: preserving and promoting musical cultural heritage.
Findings of the IWSLT 2024 Evaluation Campaign
Nov 07, 2024This paper reports on the shared tasks organized by the 21st IWSLT Conference. The shared tasks address 7 scientific challenges in spoken language translation: simultaneous and offline translation, automatic subtitling and dubbing, speech-to-speech translation, dialect and low-resource speech translation, and Indic languages. The shared tasks attracted 18 teams whose submissions are documented in 26 system papers. The growing interest towards spoken language translation is also witnessed by the constantly increasing number of shared task organizers and contributors to the overview paper, almost evenly distributed across industry and academia.
Practical End-to-End Optical Music Recognition for Pianoform Music
Mar 20, 2024



The majority of recent progress in Optical Music Recognition (OMR) has been achieved with Deep Learning methods, especially models following the end-to-end paradigm, reading input images and producing a linear sequence of tokens. Unfortunately, many music scores, especially piano music, cannot be easily converted to a linear sequence. This has led OMR researchers to use custom linearized encodings, instead of broadly accepted structured formats for music notation. Their diversity makes it difficult to compare the performance of OMR systems directly. To bring recent OMR model progress closer to useful results: (a) We define a sequential format called Linearized MusicXML, allowing to train an end-to-end model directly and maintaining close cohesion and compatibility with the industry-standard MusicXML format. (b) We create a dev and test set for benchmarking typeset OMR with MusicXML ground truth based on the OpenScore Lieder corpus. They contain 1,438 and 1,493 pianoform systems, each with an image from IMSLP. (c) We train and fine-tune an end-to-end model to serve as a baseline on the dataset and employ the TEDn metric to evaluate the model. We also test our model against the recently published synthetic pianoform dataset GrandStaff and surpass the state-of-the-art results.
Defending Compositionality in Emergent Languages
Jun 09, 2022
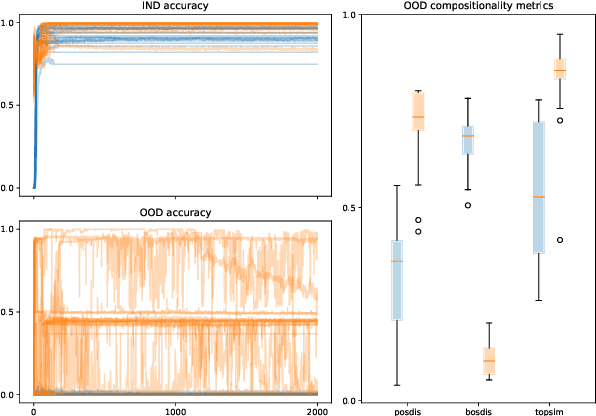
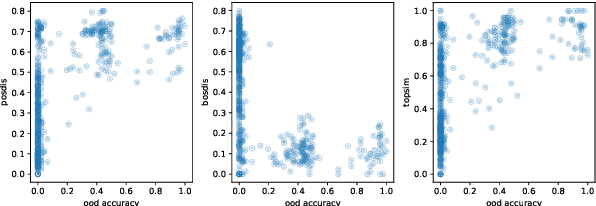

Compositionality has traditionally been understood as a major factor in productivity of language and, more broadly, human cognition. Yet, recently, some research started to question its status, showing that artificial neural networks are good at generalization even without noticeable compositional behavior. We argue that some of these conclusions are too strong and/or incomplete. In the context of a two-agent communication game, we show that compositionality indeed seems essential for successful generalization when the evaluation is done on a proper dataset.
English-Czech Systems in WMT19: Document-Level Transformer
Jul 30, 2019



We describe our NMT systems submitted to the WMT19 shared task in English-Czech news translation. Our systems are based on the Transformer model implemented in either Tensor2Tensor (T2T) or Marian framework. We aimed at improving the adequacy and coherence of translated documents by enlarging the context of the source and target. Instead of translating each sentence independently, we split the document into possibly overlapping multi-sentence segments. In case of the T2T implementation, this "document-level"-trained system achieves a $+0.6$ BLEU improvement ($p<0.05$) relative to the same system applied on isolated sentences. To assess the potential effect document-level models might have on lexical coherence, we performed a semi-automatic analysis, which revealed only a few sentences improved in this aspect. Thus, we cannot draw any conclusions from this weak evidence.
Detecting Noteheads in Handwritten Scores with ConvNets and Bounding Box Regression
Aug 05, 2017
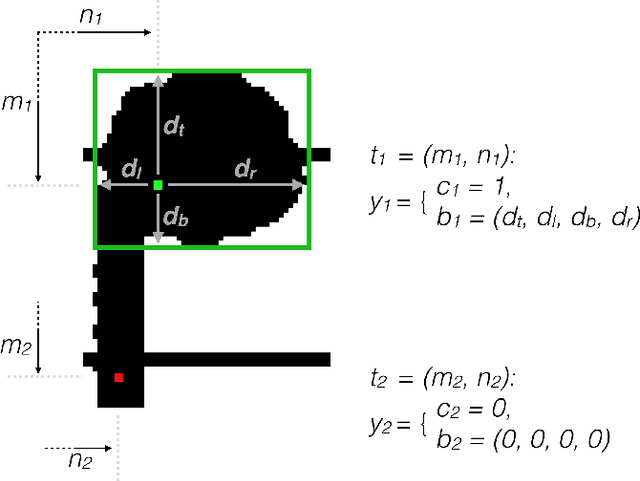
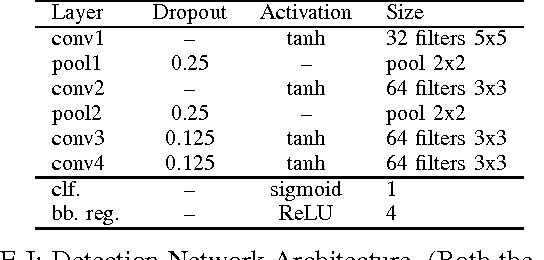
Noteheads are the interface between the written score and music. Each notehead on the page signifies one note to be played, and detecting noteheads is thus an unavoidable step for Optical Music Recognition. Noteheads are clearly distinct objects, however, the variety of music notation handwriting makes noteheads harder to identify, and while handwritten music notation symbol {\em classification} is a well-studied task, symbol {\em detection} has usually been limited to heuristics and rule-based systems instead of machine learning methods better suited to deal with the uncertainties in handwriting. We present ongoing work on a simple notehead detector using convolutional neural networks for pixel classification and bounding box regression that achieves a detection f-score of 0.97 on binary score images in the MUSCIMA++ dataset, does not require staff removal, and is applicable to a variety of handwriting styles and levels of musical complexity.
In Search of a Dataset for Handwritten Optical Music Recognition: Introducing MUSCIMA++
Mar 14, 2017
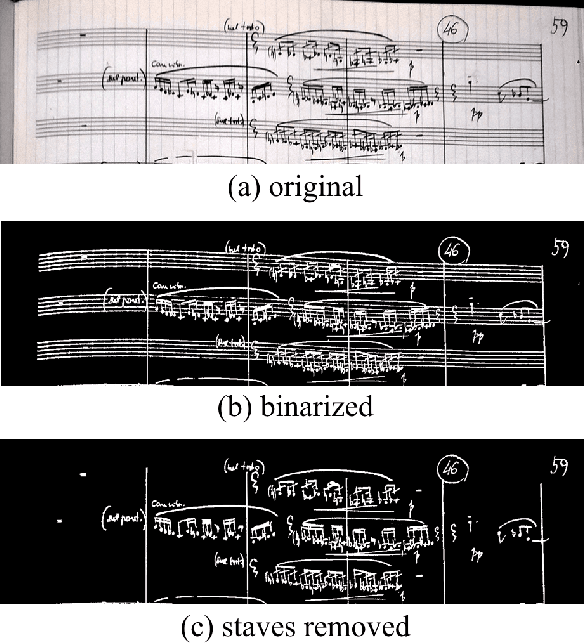

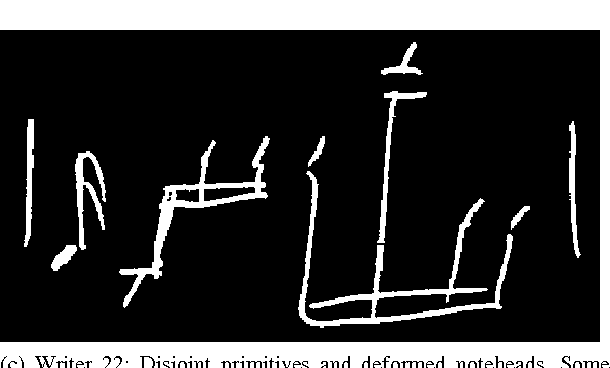
Optical Music Recognition (OMR) has long been without an adequate dataset and ground truth for evaluating OMR systems, which has been a major problem for establishing a state of the art in the field. Furthermore, machine learning methods require training data. We analyze how the OMR processing pipeline can be expressed in terms of gradually more complex ground truth, and based on this analysis, we design the MUSCIMA++ dataset of handwritten music notation that addresses musical symbol recognition and notation reconstruction. The MUSCIMA++ dataset version 0.9 consists of 140 pages of handwritten music, with 91255 manually annotated notation symbols and 82261 explicitly marked relationships between symbol pairs. The dataset allows training and evaluating models for symbol classification, symbol localization, and notation graph assembly, both in isolation and jointly. Open-source tools are provided for manipulating the dataset, visualizing the data and further annotation, and the dataset itself is made available under an open license.
CUNI System for WMT16 Automatic Post-Editing and Multimodal Translation Tasks
Jun 23, 2016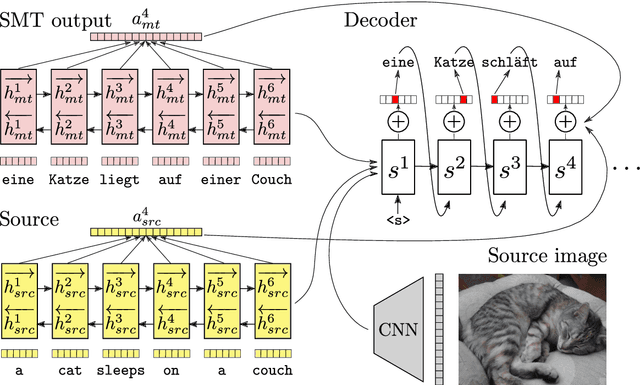
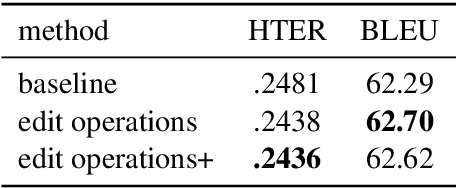

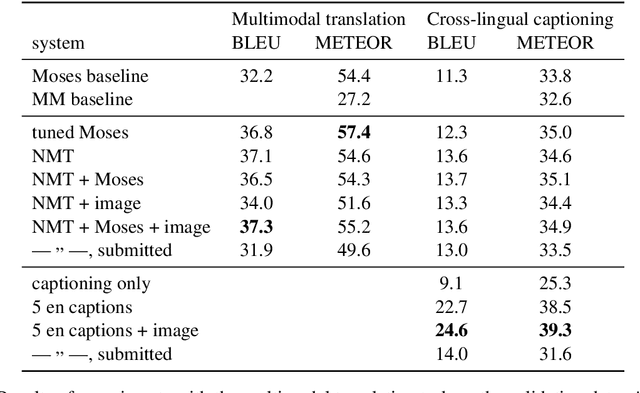
Neural sequence to sequence learning recently became a very promising paradigm in machine translation, achieving competitive results with statistical phrase-based systems. In this system description paper, we attempt to utilize several recently published methods used for neural sequential learning in order to build systems for WMT 2016 shared tasks of Automatic Post-Editing and Multimodal Machine Translation.