 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePractical End-to-End Optical Music Recognition for Pianoform Music
Mar 20, 2024



The majority of recent progress in Optical Music Recognition (OMR) has been achieved with Deep Learning methods, especially models following the end-to-end paradigm, reading input images and producing a linear sequence of tokens. Unfortunately, many music scores, especially piano music, cannot be easily converted to a linear sequence. This has led OMR researchers to use custom linearized encodings, instead of broadly accepted structured formats for music notation. Their diversity makes it difficult to compare the performance of OMR systems directly. To bring recent OMR model progress closer to useful results: (a) We define a sequential format called Linearized MusicXML, allowing to train an end-to-end model directly and maintaining close cohesion and compatibility with the industry-standard MusicXML format. (b) We create a dev and test set for benchmarking typeset OMR with MusicXML ground truth based on the OpenScore Lieder corpus. They contain 1,438 and 1,493 pianoform systems, each with an image from IMSLP. (c) We train and fine-tune an end-to-end model to serve as a baseline on the dataset and employ the TEDn metric to evaluate the model. We also test our model against the recently published synthetic pianoform dataset GrandStaff and surpass the state-of-the-art results.
In Search of a Dataset for Handwritten Optical Music Recognition: Introducing MUSCIMA++
Mar 14, 2017
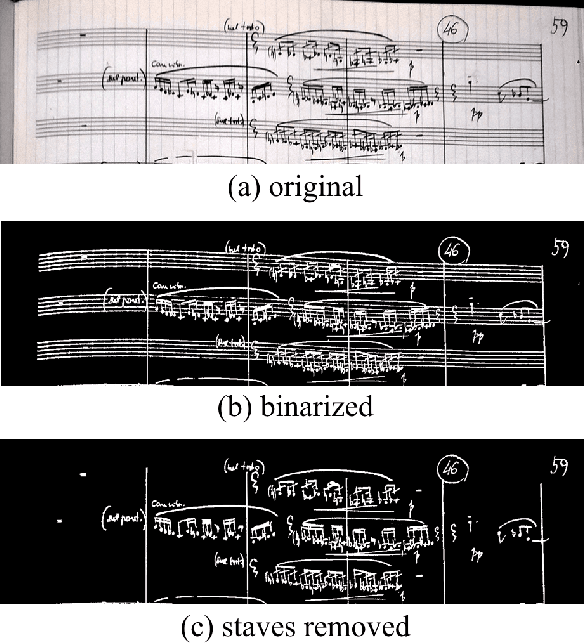

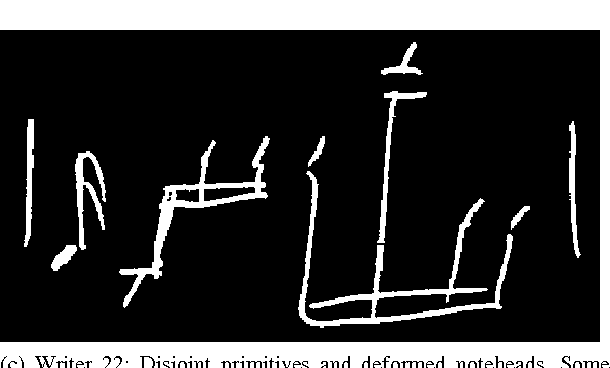
Optical Music Recognition (OMR) has long been without an adequate dataset and ground truth for evaluating OMR systems, which has been a major problem for establishing a state of the art in the field. Furthermore, machine learning methods require training data. We analyze how the OMR processing pipeline can be expressed in terms of gradually more complex ground truth, and based on this analysis, we design the MUSCIMA++ dataset of handwritten music notation that addresses musical symbol recognition and notation reconstruction. The MUSCIMA++ dataset version 0.9 consists of 140 pages of handwritten music, with 91255 manually annotated notation symbols and 82261 explicitly marked relationships between symbol pairs. The dataset allows training and evaluating models for symbol classification, symbol localization, and notation graph assembly, both in isolation and jointly. Open-source tools are provided for manipulating the dataset, visualizing the data and further annotation, and the dataset itself is made available under an open license.