 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIn Search of a Dataset for Handwritten Optical Music Recognition: Introducing MUSCIMA++
Paper and Code

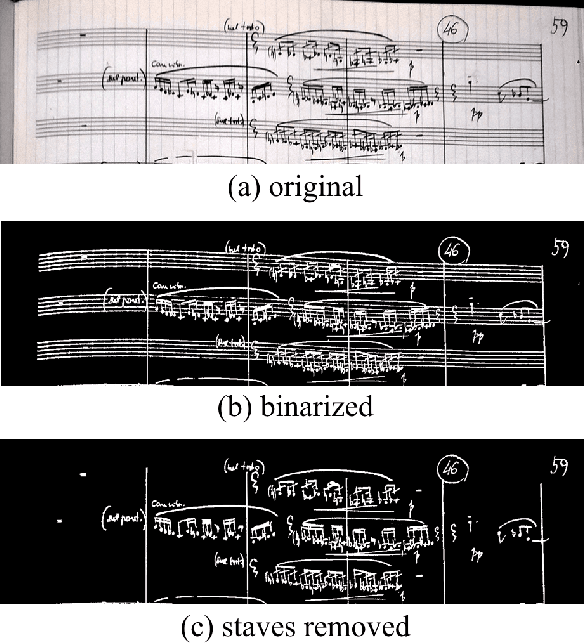

Optical Music Recognition (OMR) has long been without an adequate dataset and ground truth for evaluating OMR systems, which has been a major problem for establishing a state of the art in the field. Furthermore, machine learning methods require training data. We analyze how the OMR processing pipeline can be expressed in terms of gradually more complex ground truth, and based on this analysis, we design the MUSCIMA++ dataset of handwritten music notation that addresses musical symbol recognition and notation reconstruction. The MUSCIMA++ dataset version 0.9 consists of 140 pages of handwritten music, with 91255 manually annotated notation symbols and 82261 explicitly marked relationships between symbol pairs. The dataset allows training and evaluating models for symbol classification, symbol localization, and notation graph assembly, both in isolation and jointly. Open-source tools are provided for manipulating the dataset, visualizing the data and further annotation, and the dataset itself is made available under an open license.