 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuality and Efficiency of Manual Annotation: Pre-annotation Bias
Jun 15, 2023This paper presents an analysis of annotation using an automatic pre-annotation for a mid-level annotation complexity task -- dependency syntax annotation. It compares the annotation efforts made by annotators using a pre-annotated version (with a high-accuracy parser) and those made by fully manual annotation. The aim of the experiment is to judge the final annotation quality when pre-annotation is used. In addition, it evaluates the effect of automatic linguistically-based (rule-formulated) checks and another annotation on the same data available to the annotators, and their influence on annotation quality and efficiency. The experiment confirmed that the pre-annotation is an efficient tool for faster manual syntactic annotation which increases the consistency of the resulting annotation without reducing its quality.
Prague Dependency Treebank -- Consolidated 1.0
Jun 05, 2020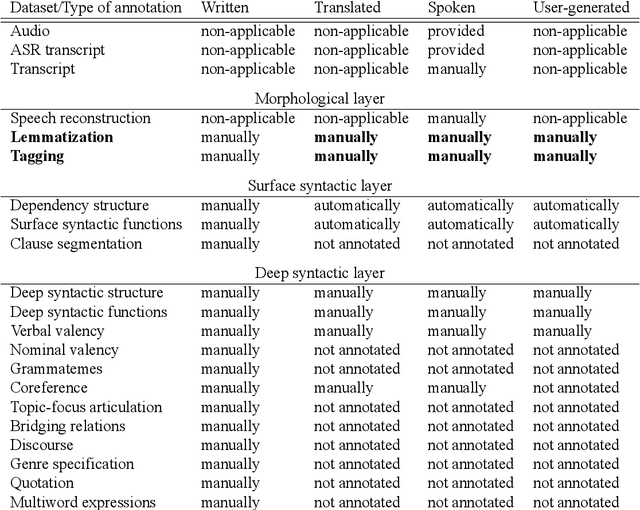



We present a richly annotated and genre-diversified language resource, the Prague Dependency Treebank-Consolidated 1.0 (PDT-C 1.0), the purpose of which is - as it always been the case for the family of the Prague Dependency Treebanks - to serve both as a training data for various types of NLP tasks as well as for linguistically-oriented research. PDT-C 1.0 contains four different datasets of Czech, uniformly annotated using the standard PDT scheme (albeit not everything is annotated manually, as we describe in detail here). The texts come from different sources: daily newspaper articles, Czech translation of the Wall Street Journal, transcribed dialogs and a small amount of user-generated, short, often non-standard language segments typed into a web translator. Altogether, the treebank contains around 180,000 sentences with their morphological, surface and deep syntactic annotation. The diversity of the texts and annotations should serve well the NLP applications as well as it is an invaluable resource for linguistic research, including comparative studies regarding texts of different genres. The corpus is publicly and freely available.