 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCharles Translator: A Machine Translation System between Ukrainian and Czech
Apr 10, 2024



We present Charles Translator, a machine translation system between Ukrainian and Czech, developed as part of a society-wide effort to mitigate the impact of the Russian-Ukrainian war on individuals and society. The system was developed in the spring of 2022 with the help of many language data providers in order to quickly meet the demand for such a service, which was not available at the time in the required quality. The translator was later implemented as an online web interface and as an Android app with speech input, both featuring Cyrillic-Latin script transliteration. The system translates directly, compared to other available systems that use English as a pivot, and thus take advantage of the typological similarity of the two languages. It uses the block back-translation method, which allows for efficient use of monolingual training data. The paper describes the development process, including data collection and implementation, evaluation, mentions several use cases, and outlines possibilities for the further development of the system for educational purposes.
Prague Dependency Treebank -- Consolidated 1.0
Jun 05, 2020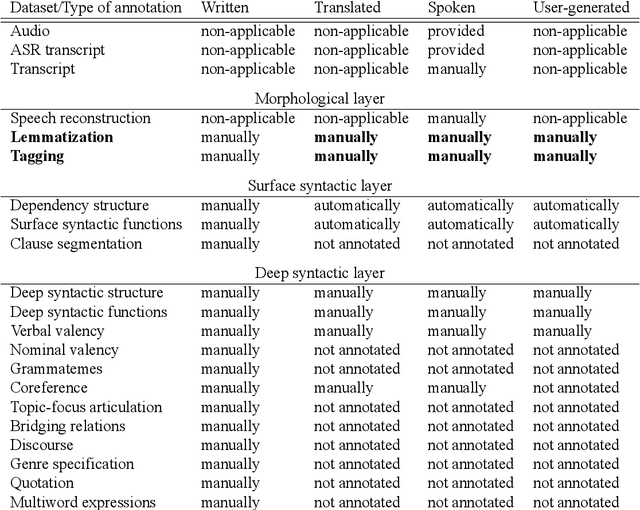



We present a richly annotated and genre-diversified language resource, the Prague Dependency Treebank-Consolidated 1.0 (PDT-C 1.0), the purpose of which is - as it always been the case for the family of the Prague Dependency Treebanks - to serve both as a training data for various types of NLP tasks as well as for linguistically-oriented research. PDT-C 1.0 contains four different datasets of Czech, uniformly annotated using the standard PDT scheme (albeit not everything is annotated manually, as we describe in detail here). The texts come from different sources: daily newspaper articles, Czech translation of the Wall Street Journal, transcribed dialogs and a small amount of user-generated, short, often non-standard language segments typed into a web translator. Altogether, the treebank contains around 180,000 sentences with their morphological, surface and deep syntactic annotation. The diversity of the texts and annotations should serve well the NLP applications as well as it is an invaluable resource for linguistic research, including comparative studies regarding texts of different genres. The corpus is publicly and freely available.