 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding the role of FFNs in driving multilingual behaviour in LLMs
Paper and Code
Apr 22, 2024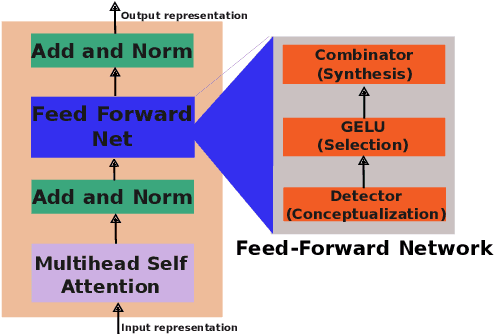
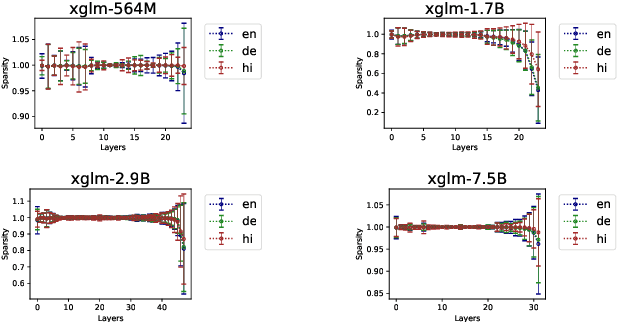
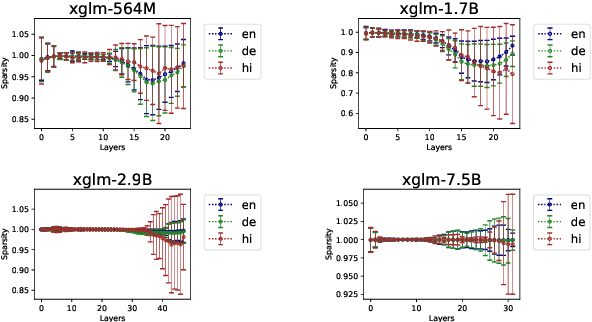
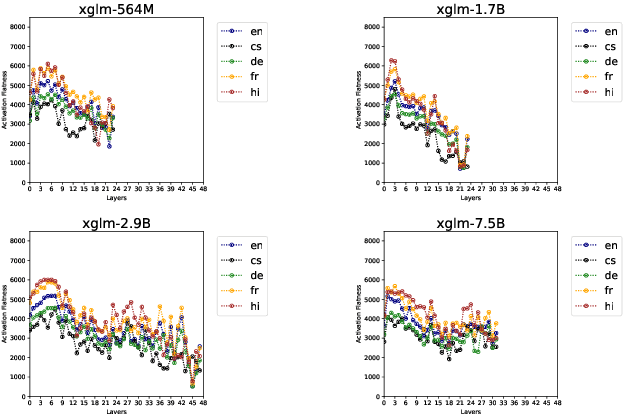
Multilingualism in Large Language Models (LLMs) is an yet under-explored area. In this paper, we conduct an in-depth analysis of the multilingual capabilities of a family of a Large Language Model, examining its architecture, activation patterns, and processing mechanisms across languages. We introduce novel metrics to probe the model's multilingual behaviour at different layers and shed light on the impact of architectural choices on multilingual processing. Our findings reveal different patterns of multilinugal processing in the sublayers of Feed-Forward Networks of the models. Furthermore, we uncover the phenomenon of "over-layerization" in certain model configurations, where increasing layer depth without corresponding adjustments to other parameters may degrade model performance. Through comparisons within and across languages, we demonstrate the interplay between model architecture, layer depth, and multilingual processing capabilities of LLMs trained on multiple languages.