 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal Shannon Game with Images
Paper and Code


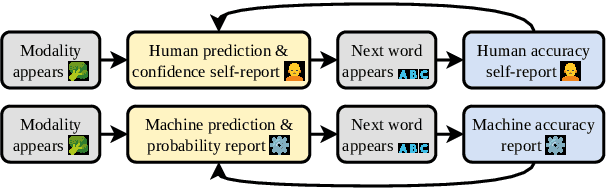

The Shannon game has long been used as a thought experiment in linguistics and NLP, asking participants to guess the next letter in a sentence based on its preceding context. We extend the game by introducing an optional extra modality in the form of image information. To investigate the impact of multimodal information in this game, we use human participants and a language model (LM, GPT-2). We show that the addition of image information improves both self-reported confidence and accuracy for both humans and LM. Certain word classes, such as nouns and determiners, benefit more from the additional modality information. The priming effect in both humans and the LM becomes more apparent as the context size (extra modality information + sentence context) increases. These findings highlight the potential of multimodal information in improving language understanding and modeling.