 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLowREm: A Repository of Word Embeddings for 87 Low-Resource Languages Enhanced with Multilingual Graph Knowledge
Paper and Code
Sep 26, 2024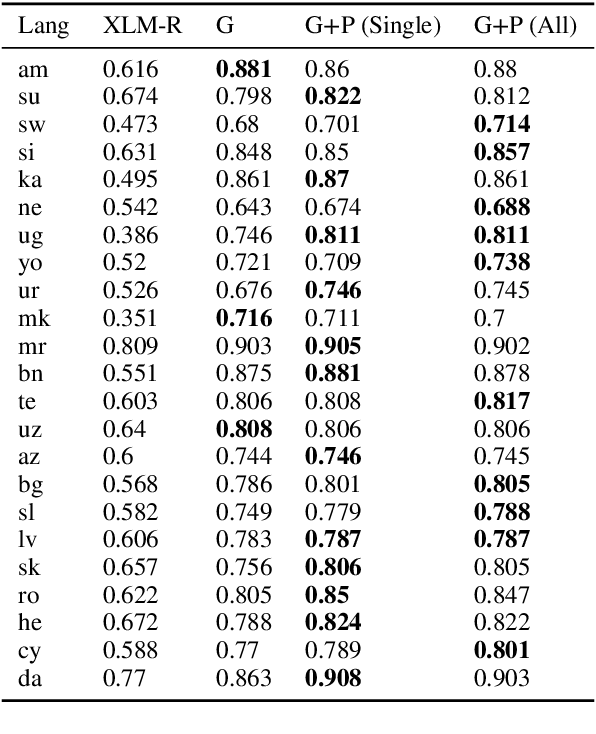
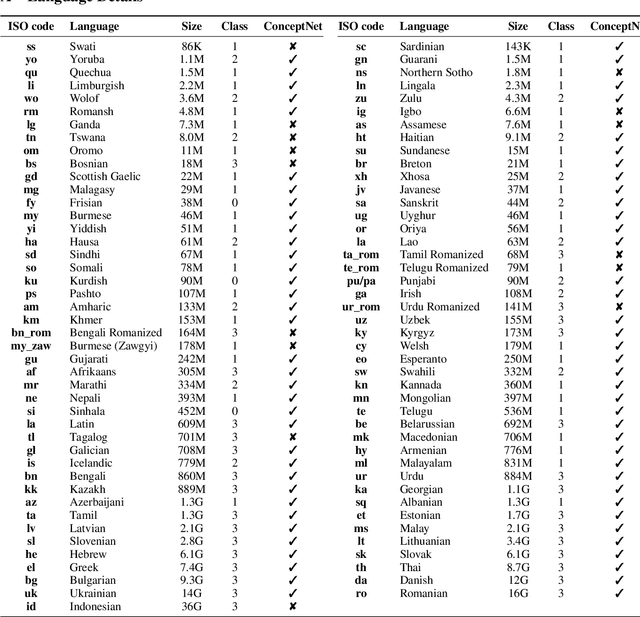
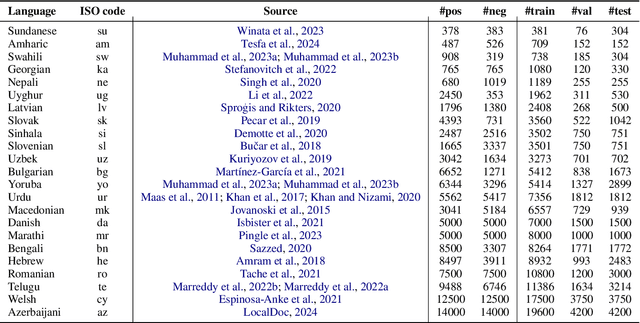
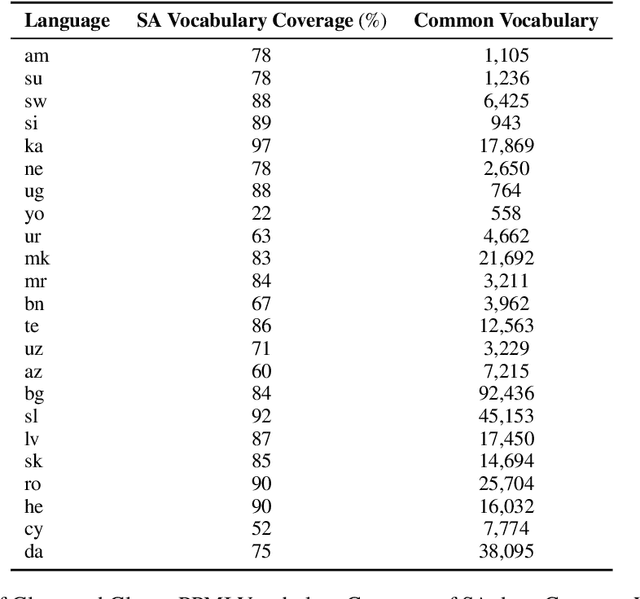
Contextualized embeddings based on large language models (LLMs) are available for various languages, but their coverage is often limited for lower resourced languages. Training LLMs for such languages is often difficult due to insufficient data and high computational cost. Especially for very low resource languages, static word embeddings thus still offer a viable alternative. There is, however, a notable lack of comprehensive repositories with such embeddings for diverse languages. To address this, we present LowREm, a centralized repository of static embeddings for 87 low-resource languages. We also propose a novel method to enhance GloVe-based embeddings by integrating multilingual graph knowledge, utilizing another source of knowledge. We demonstrate the superior performance of our enhanced embeddings as compared to contextualized embeddings extracted from XLM-R on sentiment analysis. Our code and data are publicly available under https://huggingface.co/DFKI.