 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAP-OOD: Attention Pooling for Out-of-Distribution Detection
Feb 05, 2026Out-of-distribution (OOD) detection, which maps high-dimensional data into a scalar OOD score, is critical for the reliable deployment of machine learning models. A key challenge in recent research is how to effectively leverage and aggregate token embeddings from language models to obtain the OOD score. In this work, we propose AP-OOD, a novel OOD detection method for natural language that goes beyond simple average-based aggregation by exploiting token-level information. AP-OOD is a semi-supervised approach that flexibly interpolates between unsupervised and supervised settings, enabling the use of limited auxiliary outlier data. Empirically, AP-OOD sets a new state of the art in OOD detection for text: in the unsupervised setting, it reduces the FPR95 (false positive rate at 95% true positives) from 27.84% to 4.67% on XSUM summarization, and from 77.08% to 70.37% on WMT15 En-Fr translation.
Leveraging Deep Operator Networks (DeepONet) for Acoustic Full Waveform Inversion (FWI)
Apr 14, 2025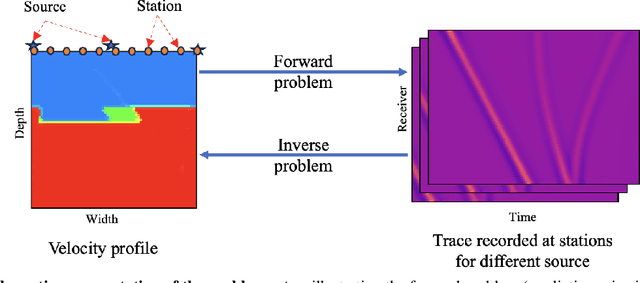
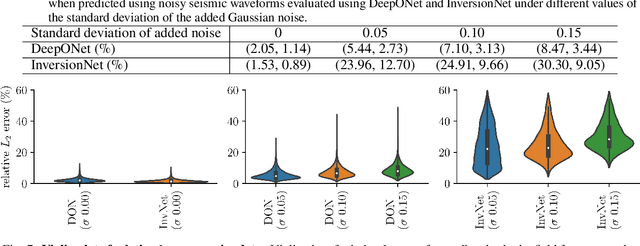
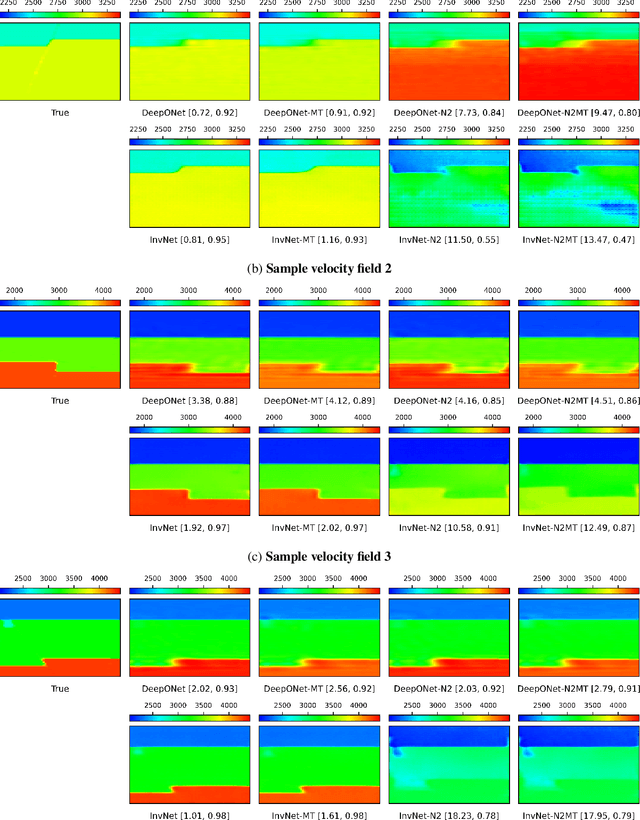
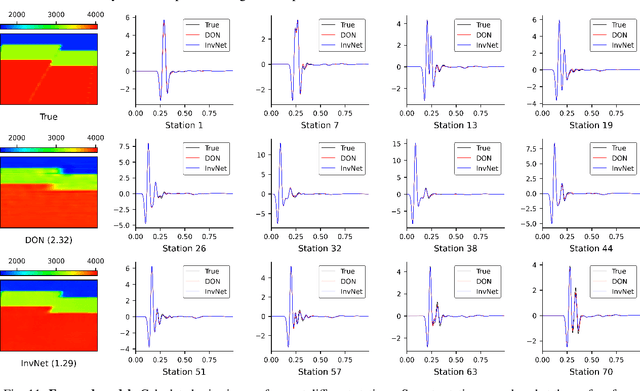
Full Waveform Inversion (FWI) is an important geophysical technique considered in subsurface property prediction. It solves the inverse problem of predicting high-resolution Earth interior models from seismic data. Traditional FWI methods are computationally demanding. Inverse problems in geophysics often face challenges of non-uniqueness due to limited data, as data are often collected only on the surface. In this study, we introduce a novel methodology that leverages Deep Operator Networks (DeepONet) to attempt to improve both the efficiency and accuracy of FWI. The proposed DeepONet methodology inverts seismic waveforms for the subsurface velocity field. This approach is able to capture some key features of the subsurface velocity field. We have shown that the architecture can be applied to noisy seismic data with an accuracy that is better than some other machine learning methods. We also test our proposed method with out-of-distribution prediction for different velocity models. The proposed DeepONet shows comparable and better accuracy in some velocity models than some other machine learning methods. To improve the FWI workflow, we propose using the DeepONet output as a starting model for conventional FWI and that it may improve FWI performance. While we have only shown that DeepONet facilitates faster convergence than starting with a homogeneous velocity field, it may have some benefits compared to other approaches to constructing starting models. This integration of DeepONet into FWI may accelerate the inversion process and may also enhance its robustness and reliability.
Titanic Calling: Low Bandwidth Video Conference from the Titanic Wreck
Oct 15, 2024



In this paper, we report on communication experiments conducted in the summer of 2022 during a deep dive to the wreck of the Titanic. Radio transmission is not possible in deep sea water, and communication links rely on sonar signals. Due to the low bandwidth of sonar signals and the need to communicate readable data, text messaging is used in deep-sea missions. In this paper, we report results and experiences from a messaging system that converts speech to text in a submarine, sends text messages to the surface, and reconstructs those messages as synthetic lip-synchronous videos of the speakers. The resulting system was tested during an actual dive to Titanic in the summer of 2022. We achieved an acceptable latency for a system of such complexity as well as good quality. The system demonstration video can be found at the following link: https://youtu.be/C4lyM86-5Ig
Handling Numeric Expressions in Automatic Speech Recognition
Jul 18, 2024This paper addresses the problem of correctly formatting numeric expressions in automatic speech recognition (ASR) transcripts. This is challenging since the expected transcript format depends on the context, e.g., 1945 (year) vs. 19:45 (timestamp). We compare cascaded and end-to-end approaches to recognize and format numeric expression, such as years, timestamps, currency amounts, and quantities. For the end-to-end approach we employed a data generation strategy using a large language model (LLM) together with a text to speech (TTS) model to generate adaptation data. The results on our test dataset show that while approaches based on LLMs perform well on recognizing formatted numeric expressions, adapted end-to-end models offer competitive performance with the advantage of lower latency and inference cost.
Continuously Learning New Words in Automatic Speech Recognition
Jan 09, 2024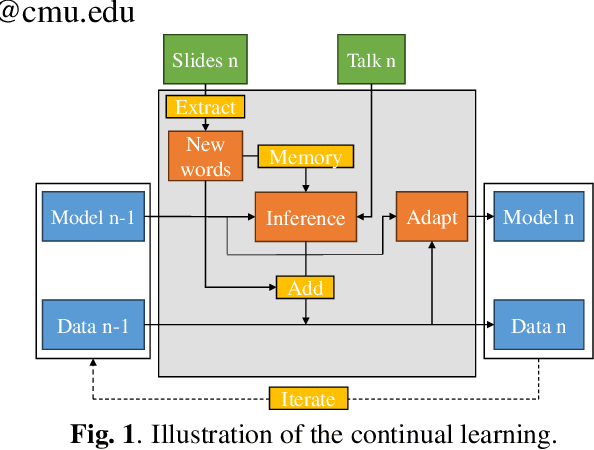
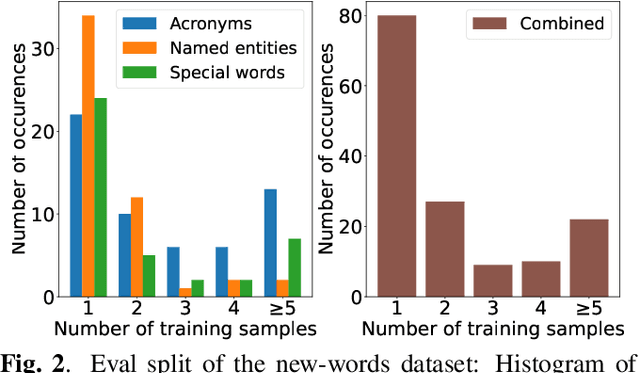
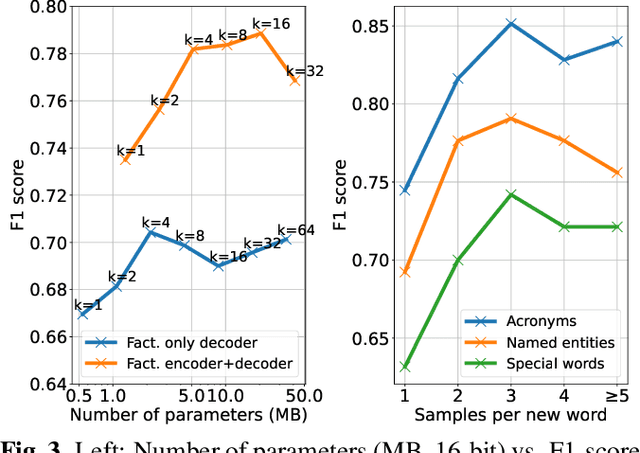
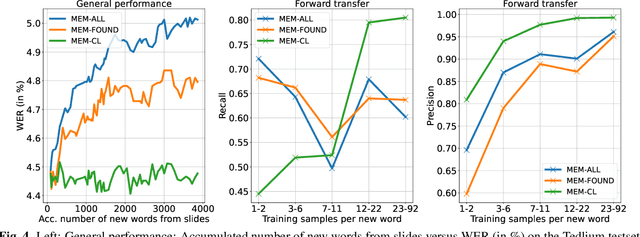
Despite recent advances, Automatic Speech Recognition (ASR) systems are still far from perfect. Typical errors include acronyms, named entities and domain-specific special words for which little or no data is available. To address the problem of recognizing these words, we propose an self-supervised continual learning approach. Given the audio of a lecture talk with corresponding slides, we bias the model towards decoding new words from the slides by using a memory-enhanced ASR model from previous work. Then, we perform inference on the talk, collecting utterances that contain detected new words into an adaptation dataset. Continual learning is then performed on this set by adapting low-rank matrix weights added to each weight matrix of the model. The whole procedure is iterated for many talks. We show that with this approach, we obtain increasing performance on the new words when they occur more frequently (more than 80% recall) while preserving the general performance of the model.
End-to-End Evaluation for Low-Latency Simultaneous Speech Translation
Aug 07, 2023The challenge of low-latency speech translation has recently draw significant interest in the research community as shown by several publications and shared tasks. Therefore, it is essential to evaluate these different approaches in realistic scenarios. However, currently only specific aspects of the systems are evaluated and often it is not possible to compare different approaches. In this work, we propose the first framework to perform and evaluate the various aspects of low-latency speech translation under realistic conditions. The evaluation is carried out in an end-to-end fashion. This includes the segmentation of the audio as well as the run-time of the different components. Secondly, we compare different approaches to low-latency speech translation using this framework. We evaluate models with the option to revise the output as well as methods with fixed output. Furthermore, we directly compare state-of-the-art cascaded as well as end-to-end systems. Finally, the framework allows to automatically evaluate the translation quality as well as latency and also provides a web interface to show the low-latency model outputs to the user.
Language-agnostic Code-Switching in End-To-End Speech Recognition
Oct 17, 2022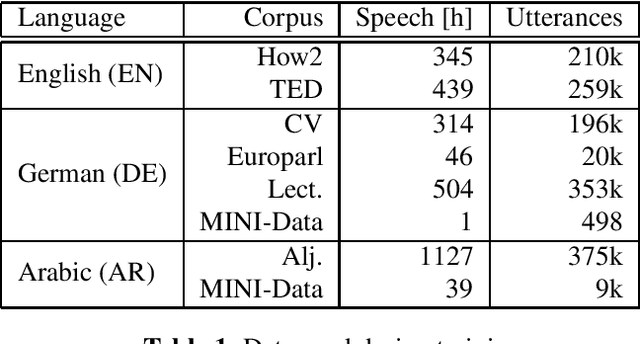
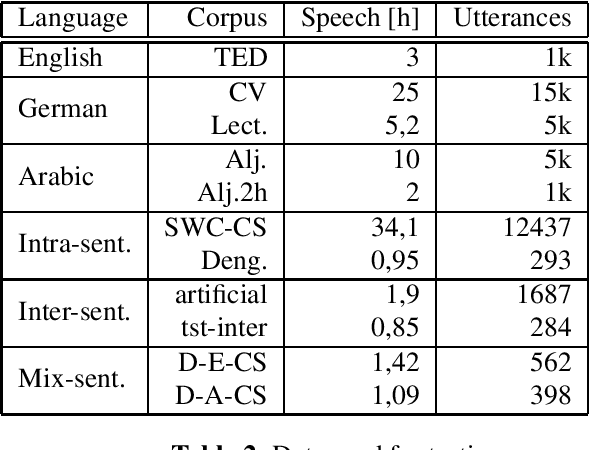
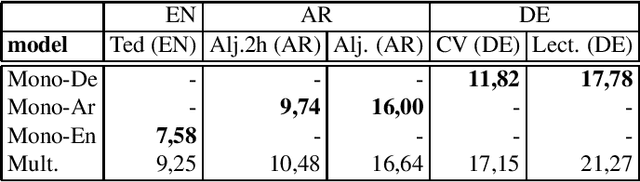
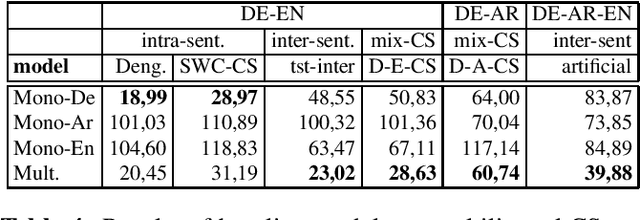
Code-Switching (CS) is referred to the phenomenon of alternately using words and phrases from different languages. While today's neural end-to-end (E2E) models deliver state-of-the-art performances on the task of automatic speech recognition (ASR) it is commonly known that these systems are very data-intensive. However, there is only a few transcribed and aligned CS speech available. To overcome this problem and train multilingual systems which can transcribe CS speech, we propose a simple yet effective data augmentation in which audio and corresponding labels of different source languages are concatenated. By using this training data, our E2E model improves on transcribing CS speech and improves performance over the multilingual model, as well. The results show that this augmentation technique can even improve the model's performance on inter-sentential language switches not seen during training by 5,03\% WER.
Code-Switching without Switching: Language Agnostic End-to-End Speech Translation
Oct 04, 2022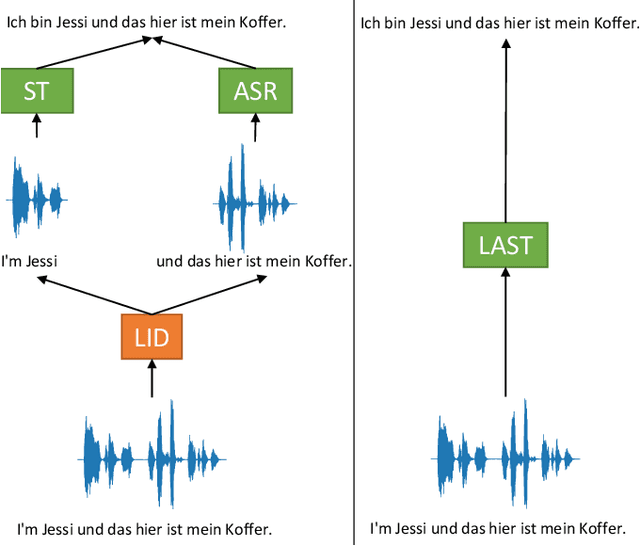
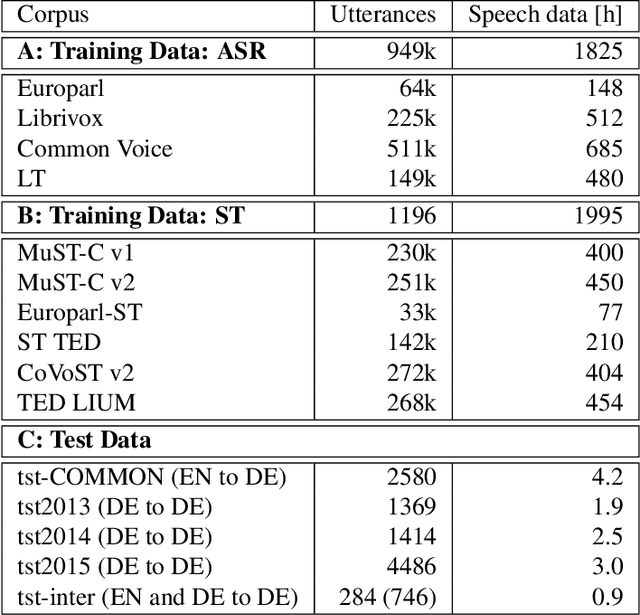
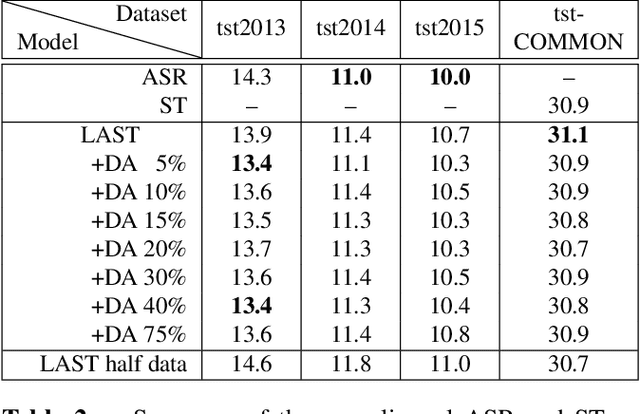
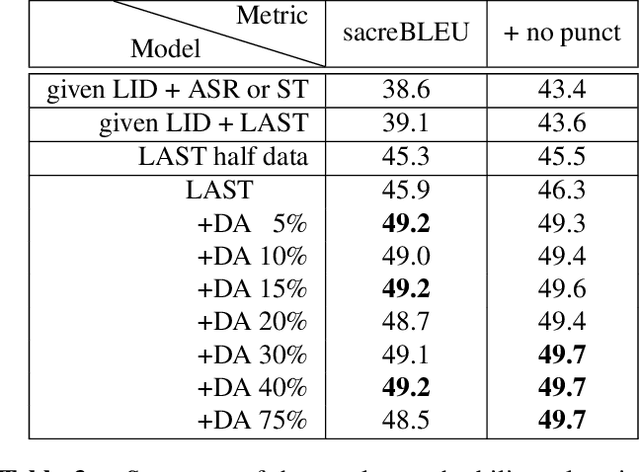
We propose a) a Language Agnostic end-to-end Speech Translation model (LAST), and b) a data augmentation strategy to increase code-switching (CS) performance. With increasing globalization, multiple languages are increasingly used interchangeably during fluent speech. Such CS complicates traditional speech recognition and translation, as we must recognize which language was spoken first and then apply a language-dependent recognizer and subsequent translation component to generate the desired target language output. Such a pipeline introduces latency and errors. In this paper, we eliminate the need for that, by treating speech recognition and translation as one unified end-to-end speech translation problem. By training LAST with both input languages, we decode speech into one target language, regardless of the input language. LAST delivers comparable recognition and speech translation accuracy in monolingual usage, while reducing latency and error rate considerably when CS is observed.
Short-Term Word-Learning in a Dynamically Changing Environment
Mar 29, 2022



Neural sequence-to-sequence automatic speech recognition (ASR) systems are in principle open vocabulary systems, when using appropriate modeling units. In practice, however, they often fail to recognize words not seen during training, e.g., named entities, numbers or technical terms. To alleviate this problem, Huber et al. proposed to supplement an end-to-end ASR system with a word/phrase memory and a mechanism to access this memory to recognize the words and phrases correctly. In this paper we study, a) methods to acquire important words for this memory dynamically and, b) the trade-off between improvement in recognition accuracy of new words and the potential danger of false alarms for those added words. We demonstrate significant improvements in the detection rate of new words with only a minor increase in false alarms (F1 score 0.30 $\rightarrow$ 0.80), when using an appropriate number of new words. In addition, we show that important keywords can be extracted from supporting documents and used effectively.
Instant One-Shot Word-Learning for Context-Specific Neural Sequence-to-Sequence Speech Recognition
Jul 05, 2021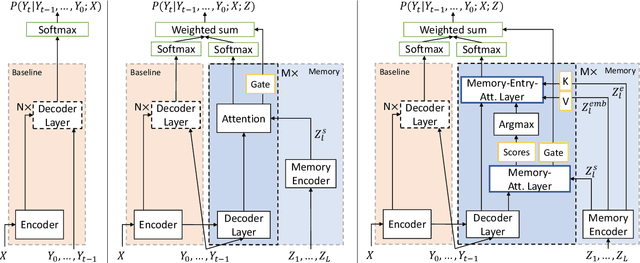
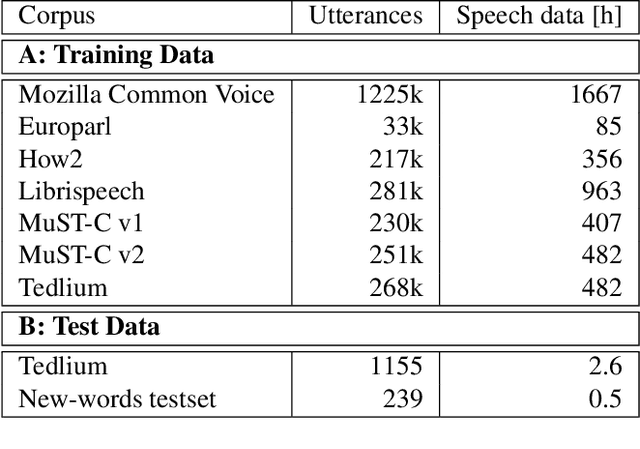
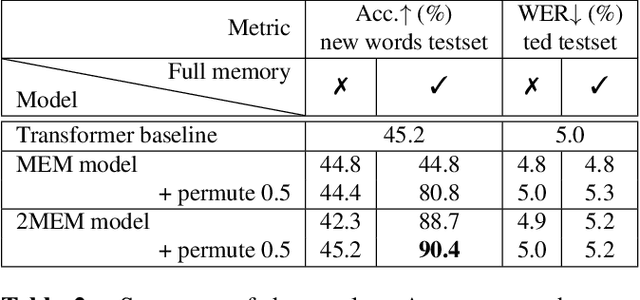
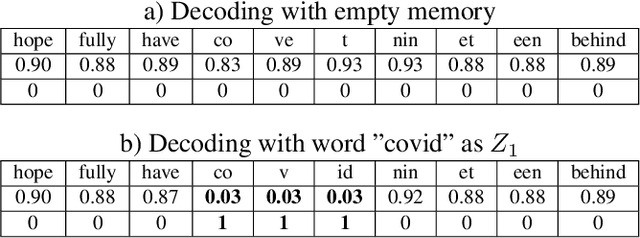
Neural sequence-to-sequence systems deliver state-of-the-art performance for automatic speech recognition (ASR). When using appropriate modeling units, e.g., byte-pair encoded characters, these systems are in principal open vocabulary systems. In practice, however, they often fail to recognize words not seen during training, e.g., named entities, numbers or technical terms. To alleviate this problem we supplement an end-to-end ASR system with a word/phrase memory and a mechanism to access this memory to recognize the words and phrases correctly. After the training of the ASR system, and when it has already been deployed, a relevant word can be added or subtracted instantly without the need for further training. In this paper we demonstrate that through this mechanism our system is able to recognize more than 85% of newly added words that it previously failed to recognize compared to a strong baseline.