 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCode-Switching without Switching: Language Agnostic End-to-End Speech Translation
Paper and Code
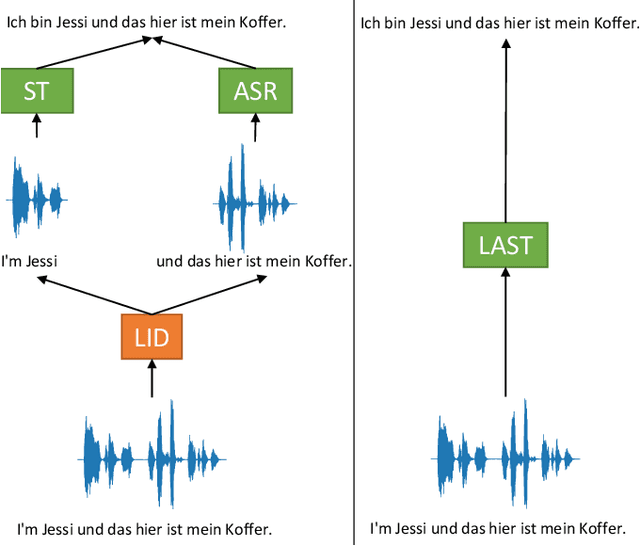
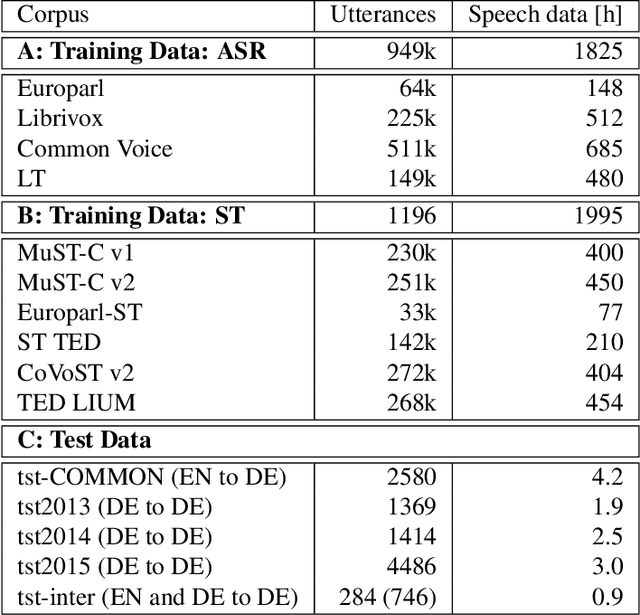
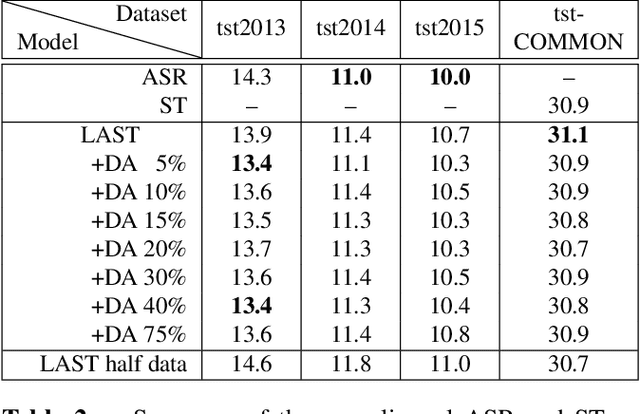
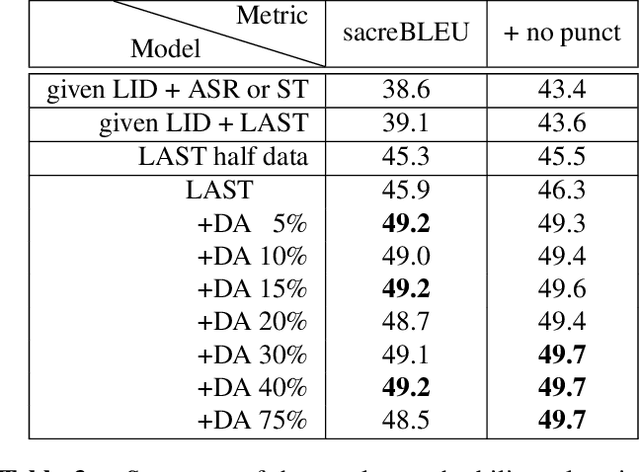
We propose a) a Language Agnostic end-to-end Speech Translation model (LAST), and b) a data augmentation strategy to increase code-switching (CS) performance. With increasing globalization, multiple languages are increasingly used interchangeably during fluent speech. Such CS complicates traditional speech recognition and translation, as we must recognize which language was spoken first and then apply a language-dependent recognizer and subsequent translation component to generate the desired target language output. Such a pipeline introduces latency and errors. In this paper, we eliminate the need for that, by treating speech recognition and translation as one unified end-to-end speech translation problem. By training LAST with both input languages, we decode speech into one target language, regardless of the input language. LAST delivers comparable recognition and speech translation accuracy in monolingual usage, while reducing latency and error rate considerably when CS is observed.