 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLanguage-agnostic Code-Switching in End-To-End Speech Recognition
Oct 17, 2022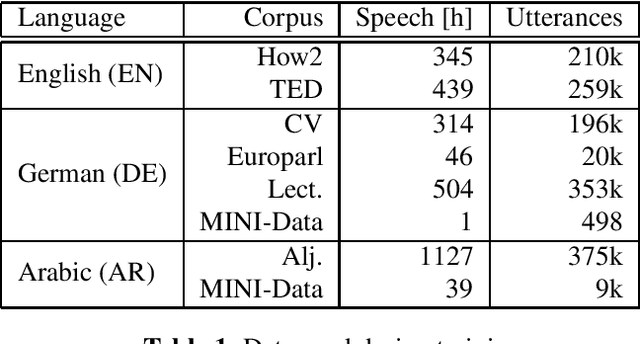
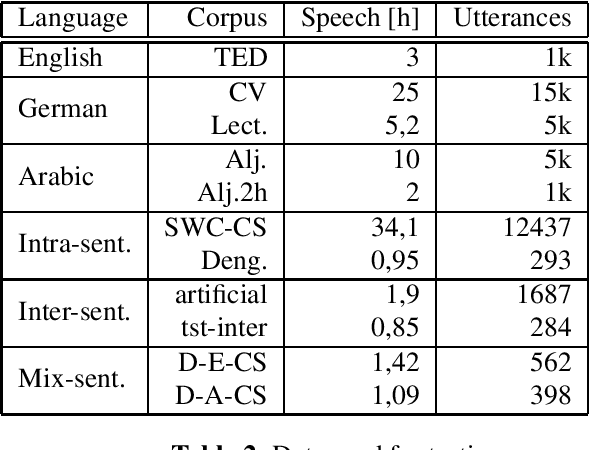
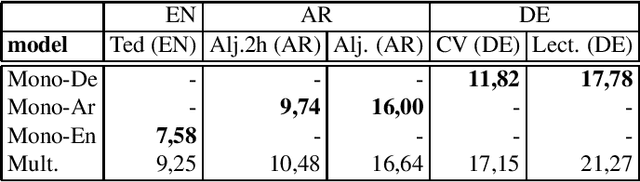
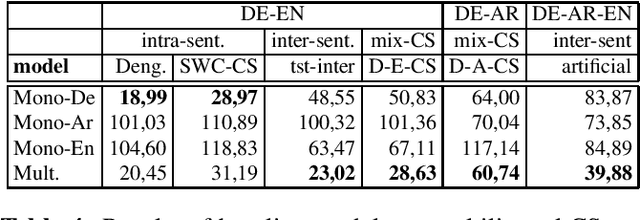
Code-Switching (CS) is referred to the phenomenon of alternately using words and phrases from different languages. While today's neural end-to-end (E2E) models deliver state-of-the-art performances on the task of automatic speech recognition (ASR) it is commonly known that these systems are very data-intensive. However, there is only a few transcribed and aligned CS speech available. To overcome this problem and train multilingual systems which can transcribe CS speech, we propose a simple yet effective data augmentation in which audio and corresponding labels of different source languages are concatenated. By using this training data, our E2E model improves on transcribing CS speech and improves performance over the multilingual model, as well. The results show that this augmentation technique can even improve the model's performance on inter-sentential language switches not seen during training by 5,03\% WER.
Instant One-Shot Word-Learning for Context-Specific Neural Sequence-to-Sequence Speech Recognition
Jul 05, 2021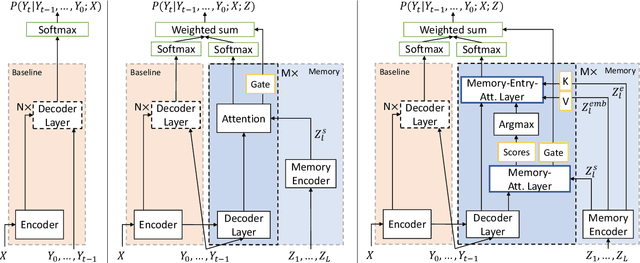
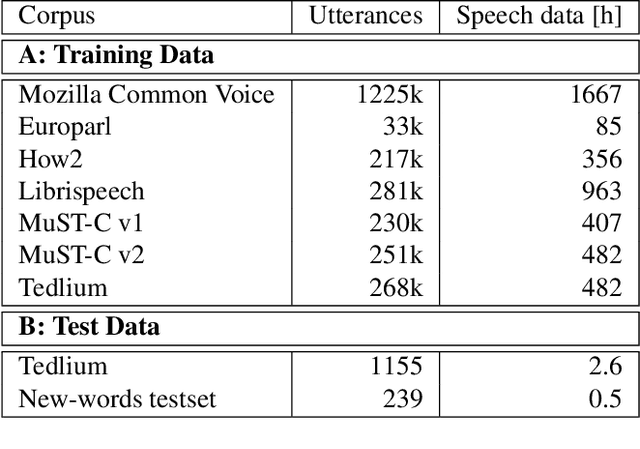
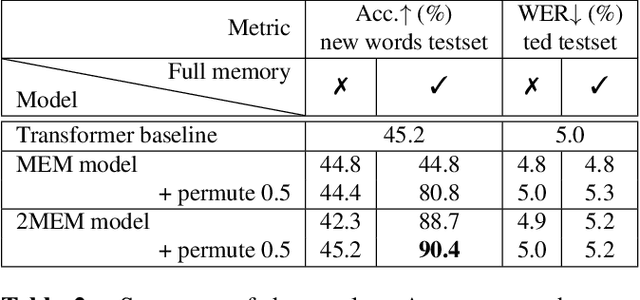
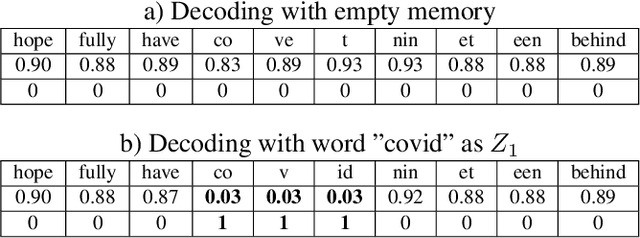
Neural sequence-to-sequence systems deliver state-of-the-art performance for automatic speech recognition (ASR). When using appropriate modeling units, e.g., byte-pair encoded characters, these systems are in principal open vocabulary systems. In practice, however, they often fail to recognize words not seen during training, e.g., named entities, numbers or technical terms. To alleviate this problem we supplement an end-to-end ASR system with a word/phrase memory and a mechanism to access this memory to recognize the words and phrases correctly. After the training of the ASR system, and when it has already been deployed, a relevant word can be added or subtracted instantly without the need for further training. In this paper we demonstrate that through this mechanism our system is able to recognize more than 85% of newly added words that it previously failed to recognize compared to a strong baseline.