 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultilingual Long-Form Speech Instruction Following: KIT's Submission to IWSLT 2026
Jun 03, 2026With the advent of Large Language Models, single-task and token-based multi-task models have evolved into instruction-based systems that infer task and target language implicitly from natural language prompts. This trend is reflected in IWSLT's Instruction Following Track, which this year introduced new tasks including an unknown surprise task, posing a genuine challenge against overfitting to known tasks. We present KIT's submission to the Long and Short Instruction Following tracks in the unconstrained setting. Our approach combines a general data augmentation pipeline that converts short-form corpora into long-form training data through segment concatenation, LLM-based label generation, and cross-lingual translation, yielding over 1M instances across six tasks and four languages. We further show that likelihood-based re-ranking, while highly effective for ASR, systematically degrades semantic tasks by spuriously selecting candidates generated from segmented audio processing rather than holistic long-form inference, a failure mode resolved by combining likelihood with Minimum Bayes Risk decoding.
Do What I Say: A Spoken Prompt Dataset for Instruction-Following
Mar 10, 2026Speech Large Language Models (SLLMs) have rapidly expanded, supporting a wide range of tasks. These models are typically evaluated using text prompts, which may not reflect real-world scenarios where users interact with speech. To address this gap, we introduce DoWhatISay (DOWIS), a multilingual dataset of human-recorded spoken and written prompts designed to pair with any existing benchmark for realistic evaluation of SLLMs under spoken instruction conditions. Spanning 9 tasks and 11 languages, it provides 10 prompt variants per task-language pair, across five styles. Using DOWIS, we benchmark state-of-the-art SLLMs, analyzing the interplay between prompt modality, style, language, and task type. Results show that text prompts consistently outperform spoken prompts, particularly for low-resource and cross-lingual settings. Only for tasks with speech output, spoken prompts do close the gap, highlighting the need for speech-based prompting in SLLM evaluation.
Beyond Transcripts: A Renewed Perspective on Audio Chaptering
Feb 09, 2026Audio chaptering, the task of automatically segmenting long-form audio into coherent sections, is increasingly important for navigating podcasts, lectures, and videos. Despite its relevance, research remains limited and text-based, leaving key questions unresolved about leveraging audio information, handling ASR errors, and transcript-free evaluation. We address these gaps through three contributions: (1) a systematic comparison between text-based models with acoustic features, a novel audio-only architecture (AudioSeg) operating on learned audio representations, and multimodal LLMs; (2) empirical analysis of factors affecting performance, including transcript quality, acoustic features, duration, and speaker composition; and (3) formalized evaluation protocols contrasting transcript-dependent text-space protocols with transcript-invariant time-space protocols. Our experiments on YTSeg reveal that AudioSeg substantially outperforms text-based approaches, pauses provide the largest acoustic gains, and MLLMs remain limited by context length and weak instruction following, yet MLLMs are promising on shorter audio.
Paragraph Segmentation Revisited: Towards a Standard Task for Structuring Speech
Dec 30, 2025Automatic speech transcripts are often delivered as unstructured word streams that impede readability and repurposing. We recast paragraph segmentation as the missing structuring step and fill three gaps at the intersection of speech processing and text segmentation. First, we establish TEDPara (human-annotated TED talks) and YTSegPara (YouTube videos with synthetic labels) as the first benchmarks for the paragraph segmentation task. The benchmarks focus on the underexplored speech domain, where paragraph segmentation has traditionally not been part of post-processing, while also contributing to the wider text segmentation field, which still lacks robust and naturalistic benchmarks. Second, we propose a constrained-decoding formulation that lets large language models insert paragraph breaks while preserving the original transcript, enabling faithful, sentence-aligned evaluation. Third, we show that a compact model (MiniSeg) attains state-of-the-art accuracy and, when extended hierarchically, jointly predicts chapters and paragraphs with minimal computational cost. Together, our resources and methods establish paragraph segmentation as a standardized, practical task in speech processing.
The AI Co-Ethnographer: How Far Can Automation Take Qualitative Research?
Apr 21, 2025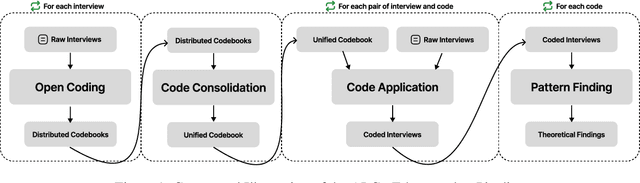
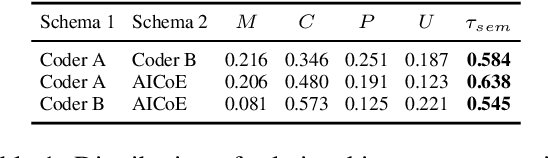
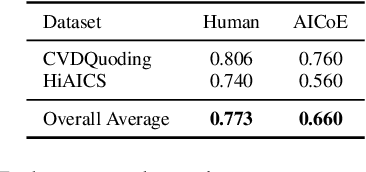
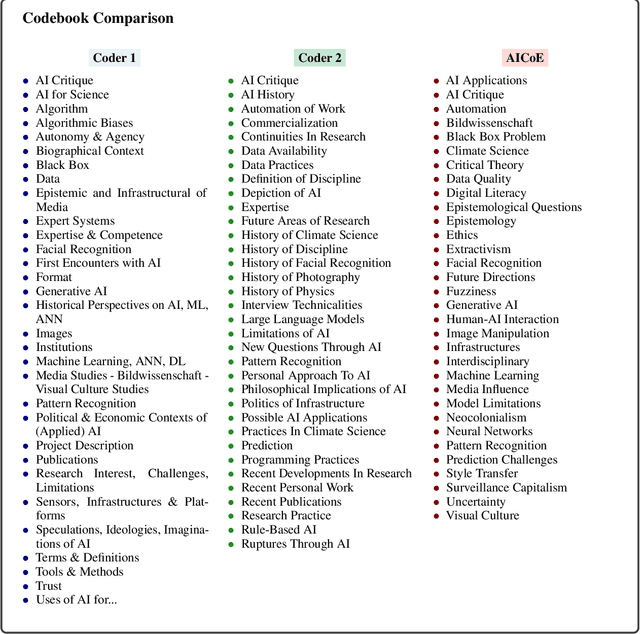
Qualitative research often involves labor-intensive processes that are difficult to scale while preserving analytical depth. This paper introduces The AI Co-Ethnographer (AICoE), a novel end-to-end pipeline developed for qualitative research and designed to move beyond the limitations of simply automating code assignments, offering a more integrated approach. AICoE organizes the entire process, encompassing open coding, code consolidation, code application, and even pattern discovery, leading to a comprehensive analysis of qualitative data.
From Speech to Summary: A Comprehensive Survey of Speech Summarization
Apr 10, 2025Speech summarization has become an essential tool for efficiently managing and accessing the growing volume of spoken and audiovisual content. However, despite its increasing importance, speech summarization is still not clearly defined and intersects with several research areas, including speech recognition, text summarization, and specific applications like meeting summarization. This survey not only examines existing datasets and evaluation methodologies, which are crucial for assessing the effectiveness of summarization approaches but also synthesizes recent developments in the field, highlighting the shift from traditional systems to advanced models like fine-tuned cascaded architectures and end-to-end solutions.
Zero-Shot Strategies for Length-Controllable Summarization
Dec 31, 2024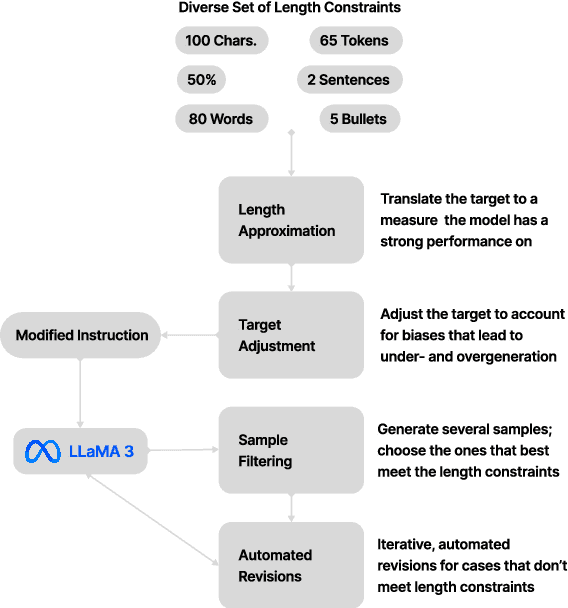

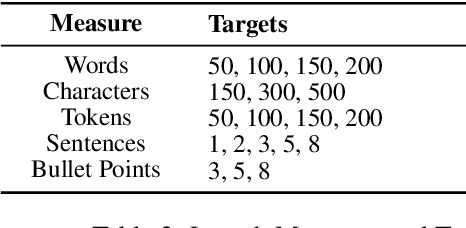
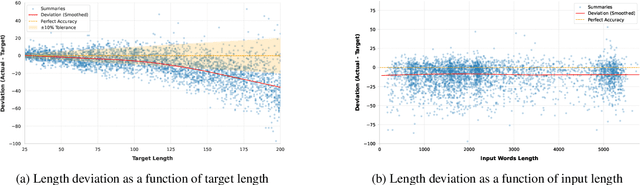
Large language models (LLMs) struggle with precise length control, particularly in zero-shot settings. We conduct a comprehensive study evaluating LLMs' length control capabilities across multiple measures and propose practical methods to improve controllability. Our experiments with LLaMA 3 reveal stark differences in length adherence across measures and highlight inherent biases of the model. To address these challenges, we introduce a set of methods: length approximation, target adjustment, sample filtering, and automated revisions. By combining these methods, we demonstrate substantial improvements in length compliance while maintaining or enhancing summary quality, providing highly effective zero-shot strategies for precise length control without the need for model fine-tuning or architectural changes. With our work, we not only advance our understanding of LLM behavior in controlled text generation but also pave the way for more reliable and adaptable summarization systems in real-world applications.
Titanic Calling: Low Bandwidth Video Conference from the Titanic Wreck
Oct 15, 2024



In this paper, we report on communication experiments conducted in the summer of 2022 during a deep dive to the wreck of the Titanic. Radio transmission is not possible in deep sea water, and communication links rely on sonar signals. Due to the low bandwidth of sonar signals and the need to communicate readable data, text messaging is used in deep-sea missions. In this paper, we report results and experiences from a messaging system that converts speech to text in a submarine, sends text messages to the surface, and reconstructs those messages as synthetic lip-synchronous videos of the speakers. The resulting system was tested during an actual dive to Titanic in the summer of 2022. We achieved an acceptable latency for a system of such complexity as well as good quality. The system demonstration video can be found at the following link: https://youtu.be/C4lyM86-5Ig
From Text Segmentation to Smart Chaptering: A Novel Benchmark for Structuring Video Transcriptions
Feb 27, 2024
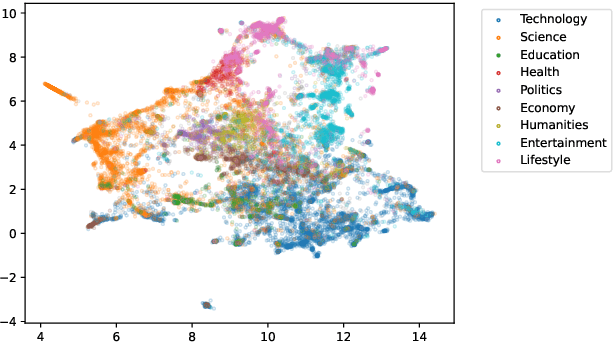
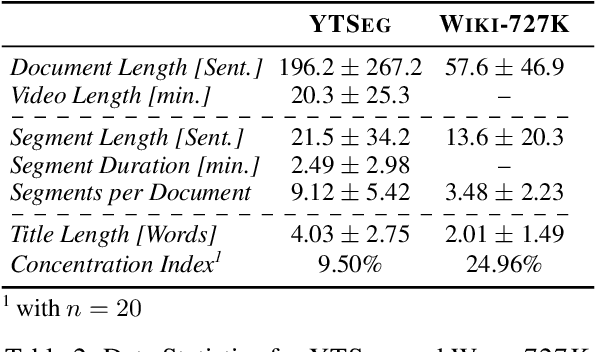
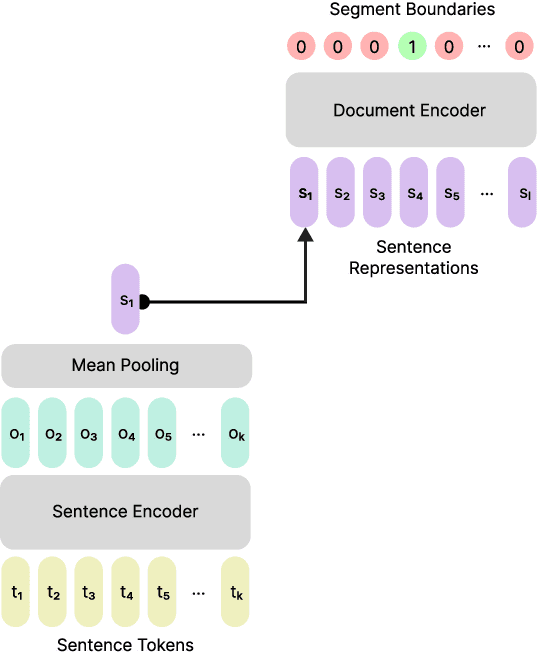
Text segmentation is a fundamental task in natural language processing, where documents are split into contiguous sections. However, prior research in this area has been constrained by limited datasets, which are either small in scale, synthesized, or only contain well-structured documents. In this paper, we address these limitations by introducing a novel benchmark YTSeg focusing on spoken content that is inherently more unstructured and both topically and structurally diverse. As part of this work, we introduce an efficient hierarchical segmentation model MiniSeg, that outperforms state-of-the-art baselines. Lastly, we expand the notion of text segmentation to a more practical "smart chaptering" task that involves the segmentation of unstructured content, the generation of meaningful segment titles, and a potential real-time application of the models.
End-to-End Evaluation for Low-Latency Simultaneous Speech Translation
Aug 07, 2023The challenge of low-latency speech translation has recently draw significant interest in the research community as shown by several publications and shared tasks. Therefore, it is essential to evaluate these different approaches in realistic scenarios. However, currently only specific aspects of the systems are evaluated and often it is not possible to compare different approaches. In this work, we propose the first framework to perform and evaluate the various aspects of low-latency speech translation under realistic conditions. The evaluation is carried out in an end-to-end fashion. This includes the segmentation of the audio as well as the run-time of the different components. Secondly, we compare different approaches to low-latency speech translation using this framework. We evaluate models with the option to revise the output as well as methods with fixed output. Furthermore, we directly compare state-of-the-art cascaded as well as end-to-end systems. Finally, the framework allows to automatically evaluate the translation quality as well as latency and also provides a web interface to show the low-latency model outputs to the user.