 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContinuously Learning New Words in Automatic Speech Recognition
Paper and Code
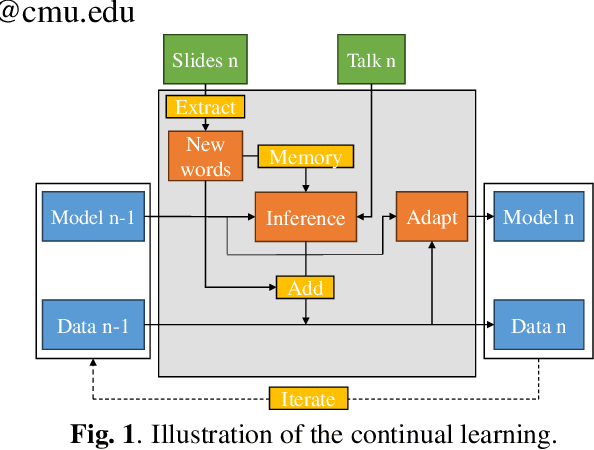
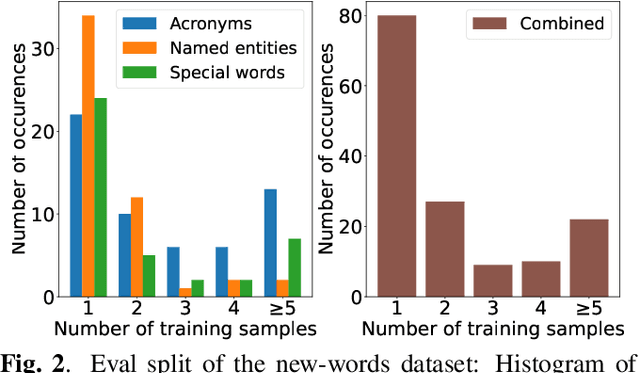
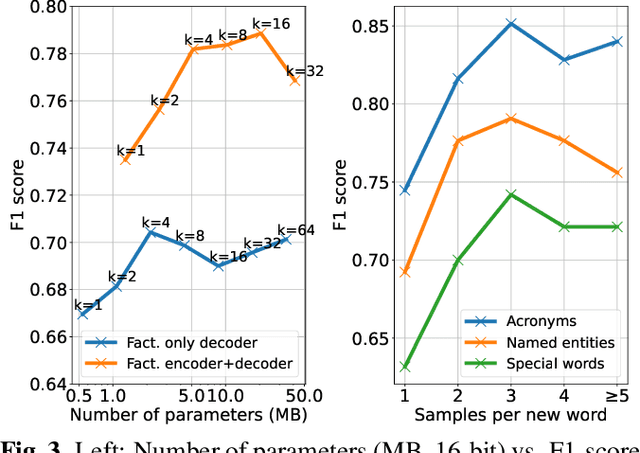
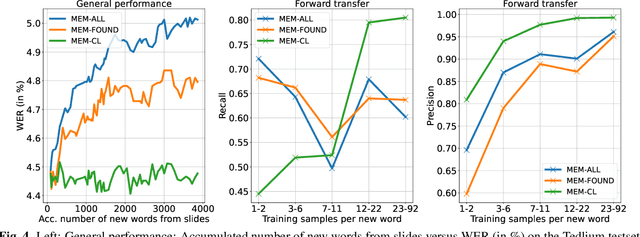
Despite recent advances, Automatic Speech Recognition (ASR) systems are still far from perfect. Typical errors include acronyms, named entities and domain-specific special words for which little or no data is available. To address the problem of recognizing these words, we propose an self-supervised continual learning approach. Given the audio of a lecture talk with corresponding slides, we bias the model towards decoding new words from the slides by using a memory-enhanced ASR model from previous work. Then, we perform inference on the talk, collecting utterances that contain detected new words into an adaptation dataset. Continual learning is then performed on this set by adapting low-rank matrix weights added to each weight matrix of the model. The whole procedure is iterated for many talks. We show that with this approach, we obtain increasing performance on the new words when they occur more frequently (more than 80% recall) while preserving the general performance of the model.