Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCurriculum Learning and Minibatch Bucketing in Neural Machine Translation
Paper and Code
Jul 29, 2017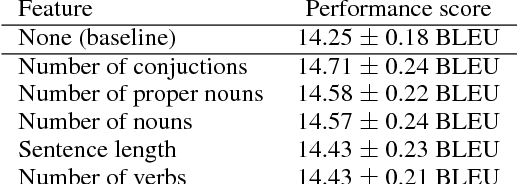
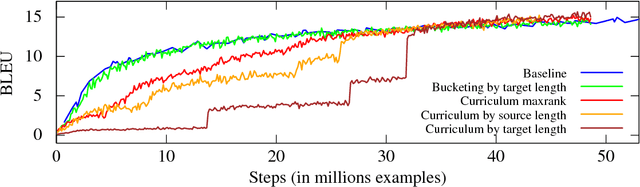

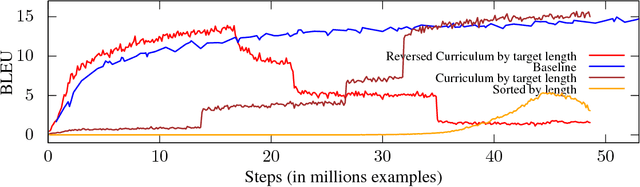
We examine the effects of particular orderings of sentence pairs on the on-line training of neural machine translation (NMT). We focus on two types of such orderings: (1) ensuring that each minibatch contains sentences similar in some aspect and (2) gradual inclusion of some sentence types as the training progresses (so called "curriculum learning"). In our English-to-Czech experiments, the internal homogeneity of minibatches has no effect on the training but some of our "curricula" achieve a small improvement over the baseline.
* Accepted to RANLP 2017
View paper on