Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnnouncing CzEng 2.0 Parallel Corpus with over 2 Gigawords
Paper and Code
Jul 06, 2020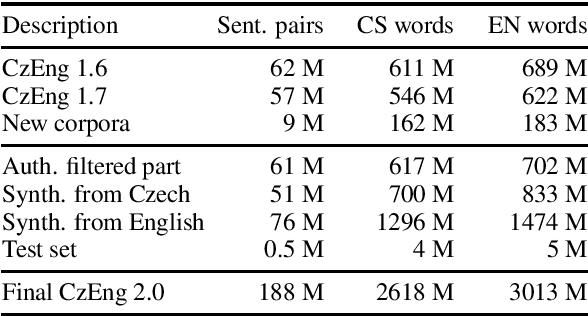
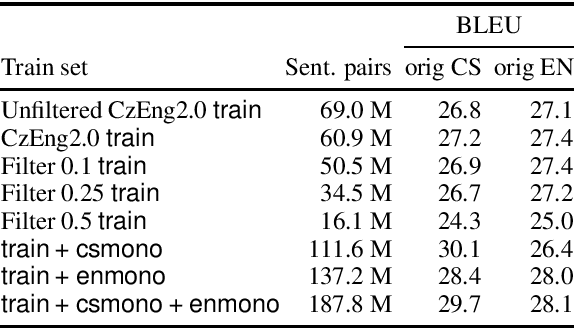
We present a new release of the Czech-English parallel corpus CzEng 2.0 consisting of over 2 billion words (2 "gigawords") in each language. The corpus contains document-level information and is filtered with several techniques to lower the amount of noise. In addition to the data in the previous version of CzEng, it contains new authentic and also high-quality synthetic parallel data. CzEng is freely available for research and educational purposes.
View paper on