 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToken-level Ensembling of Models with Different Vocabularies
Feb 28, 2025Model ensembling is a technique to combine the predicted distributions of two or more models, often leading to improved robustness and performance. For ensembling in text generation, the next token's probability distribution is derived from a weighted sum of the distributions of each individual model. This requires the underlying models to share the same subword vocabulary, limiting the applicability of ensembling, since many open-sourced models have distinct vocabularies. In research settings, experimentation or upgrades to vocabularies may introduce multiple vocabulary sizes. This paper proposes an inference-time only algorithm that allows for ensembling models with different vocabularies, without the need to learn additional parameters or alter the underlying models. Instead, the algorithm ensures that tokens generated by the ensembled models \textit{agree} in their surface form. We apply this technique to combinations of traditional encoder-decoder models and decoder-only LLMs and evaluate on machine translation. In addition to expanding to model pairs that were previously incapable of token-level ensembling, our algorithm frequently improves translation performance over either model individually.
Recovering document annotations for sentence-level bitext
Jun 06, 2024

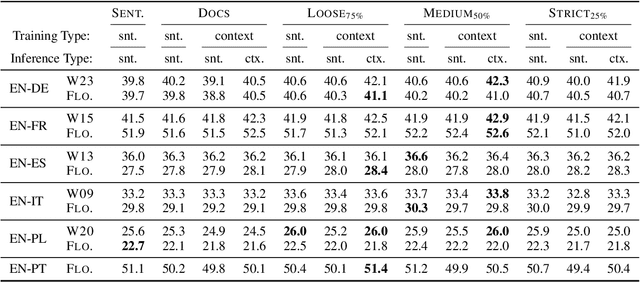

Data availability limits the scope of any given task. In machine translation, historical models were incapable of handling longer contexts, so the lack of document-level datasets was less noticeable. Now, despite the emergence of long-sequence methods, we remain within a sentence-level paradigm and without data to adequately approach context-aware machine translation. Most large-scale datasets have been processed through a pipeline that discards document-level metadata. In this work, we reconstruct document-level information for three (ParaCrawl, News Commentary, and Europarl) large datasets in German, French, Spanish, Italian, Polish, and Portuguese (paired with English). We then introduce a document-level filtering technique as an alternative to traditional bitext filtering. We present this filtering with analysis to show that this method prefers context-consistent translations rather than those that may have been sentence-level machine translated. Last we train models on these longer contexts and demonstrate improvement in document-level translation without degradation of sentence-level translation. We release our dataset, ParaDocs, and resulting models as a resource to the community.
Identifying Context-Dependent Translations for Evaluation Set Production
Nov 04, 2023



A major impediment to the transition to context-aware machine translation is the absence of good evaluation metrics and test sets. Sentences that require context to be translated correctly are rare in test sets, reducing the utility of standard corpus-level metrics such as COMET or BLEU. On the other hand, datasets that annotate such sentences are also rare, small in scale, and available for only a few languages. To address this, we modernize, generalize, and extend previous annotation pipelines to produce CTXPRO, a tool that identifies subsets of parallel documents containing sentences that require context to correctly translate five phenomena: gender, formality, and animacy for pronouns, verb phrase ellipsis, and ambiguous noun inflections. The input to the pipeline is a set of hand-crafted, per-language, linguistically-informed rules that select contextual sentence pairs using coreference, part-of-speech, and morphological features provided by state-of-the-art tools. We apply this pipeline to seven languages pairs (EN into and out-of DE, ES, FR, IT, PL, PT, and RU) and two datasets (OpenSubtitles and WMT test sets), and validate its performance using both overlap with previous work and its ability to discriminate a contextual MT system from a sentence-based one. We release the CTXPRO pipeline and data as open source.