 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSteering Large Language Models with Register Analysis for Arbitrary Style Transfer
May 01, 2025Large Language Models (LLMs) have demonstrated strong capabilities in rewriting text across various styles. However, effectively leveraging this ability for example-based arbitrary style transfer, where an input text is rewritten to match the style of a given exemplar, remains an open challenge. A key question is how to describe the style of the exemplar to guide LLMs toward high-quality rewrites. In this work, we propose a prompting method based on register analysis to guide LLMs to perform this task. Empirical evaluations across multiple style transfer tasks show that our prompting approach enhances style transfer strength while preserving meaning more effectively than existing prompting strategies.
Token-level Ensembling of Models with Different Vocabularies
Feb 28, 2025Model ensembling is a technique to combine the predicted distributions of two or more models, often leading to improved robustness and performance. For ensembling in text generation, the next token's probability distribution is derived from a weighted sum of the distributions of each individual model. This requires the underlying models to share the same subword vocabulary, limiting the applicability of ensembling, since many open-sourced models have distinct vocabularies. In research settings, experimentation or upgrades to vocabularies may introduce multiple vocabulary sizes. This paper proposes an inference-time only algorithm that allows for ensembling models with different vocabularies, without the need to learn additional parameters or alter the underlying models. Instead, the algorithm ensures that tokens generated by the ensembled models \textit{agree} in their surface form. We apply this technique to combinations of traditional encoder-decoder models and decoder-only LLMs and evaluate on machine translation. In addition to expanding to model pairs that were previously incapable of token-level ensembling, our algorithm frequently improves translation performance over either model individually.
Syllabus: Portable Curricula for Reinforcement Learning Agents
Nov 18, 2024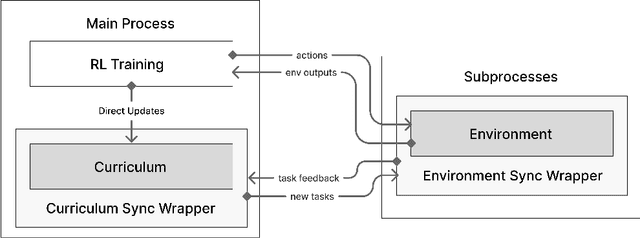


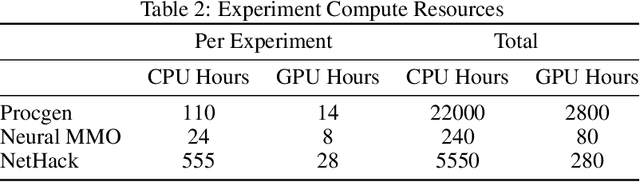
Curriculum learning has been a quiet yet crucial component of many of the high-profile successes of reinforcement learning. Despite this, none of the major reinforcement learning libraries directly support curriculum learning or include curriculum learning implementations. These methods can improve the capabilities and robustness of RL agents, but often require significant, complex changes to agent training code. We introduce Syllabus, a library for training RL agents with curriculum learning, as a solution to this problem. Syllabus provides a universal API for curriculum learning algorithms, implementations of popular curriculum learning methods, and infrastructure for easily integrating them with distributed training code written in nearly any RL library. Syllabus provides a minimal API for each of the core components of curriculum learning, dramatically simplifying the process of designing new algorithms and applying existing algorithms to new environments. We demonstrate that the same Syllabus code can be used to train agents written in multiple different RL libraries on numerous domains. In doing so, we present the first examples of curriculum learning in NetHack and Neural MMO, two of the premier challenges for single-agent and multi-agent RL respectively, achieving strong results compared to state of the art baselines.