 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Simple Method for Unsupervised Bilingual Lexicon Induction for Data-Imbalanced, Closely Related Language Pairs
Paper and Code

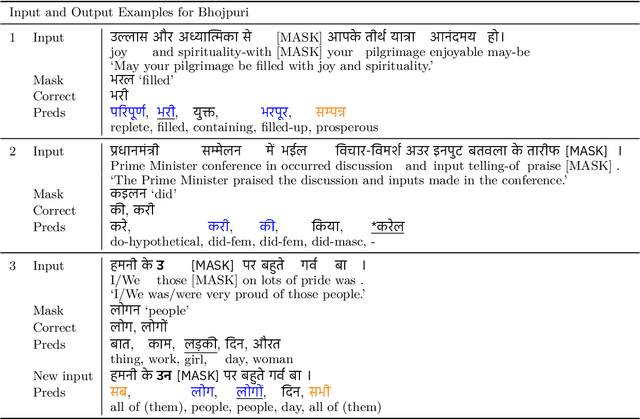
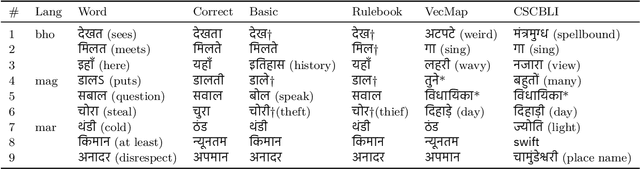

Existing approaches for unsupervised bilingual lexicon induction (BLI) often depend on good quality static or contextual embeddings trained on large monolingual corpora for both languages. In reality, however, unsupervised BLI is most likely to be useful for dialects and languages that do not have abundant amounts of monolingual data. We introduce a simple and fast method for unsupervised BLI for low-resource languages with a related mid-to-high resource language, only requiring inference on the higher-resource language monolingual BERT. We work with two low-resource languages ($<5M$ monolingual tokens), Bhojpuri and Magahi, of the severely under-researched Indic dialect continuum, showing that state-of-the-art methods in the literature show near-zero performance in these settings, and that our simpler method gives much better results. We repeat our experiments on Marathi and Nepali, two higher-resource Indic languages, to compare approach performances by resource range. We release automatically created bilingual lexicons for the first time for five languages of the Indic dialect continuum.