 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Effectiveness of Morphology-aware Segmentation in Low-Resource Neural Machine Translation
Paper and Code

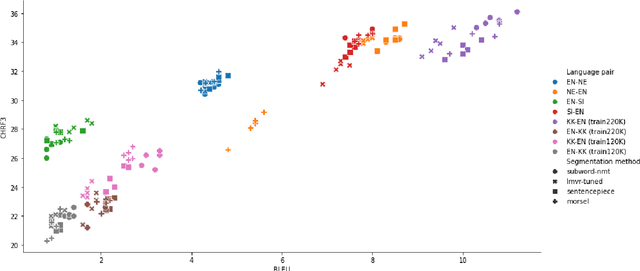

This paper evaluates the performance of several modern subword segmentation methods in a low-resource neural machine translation setting. We compare segmentations produced by applying BPE at the token or sentence level with morphologically-based segmentations from LMVR and MORSEL. We evaluate translation tasks between English and each of Nepali, Sinhala, and Kazakh, and predict that using morphologically-based segmentation methods would lead to better performance in this setting. However, comparing to BPE, we find that no consistent and reliable differences emerge between the segmentation methods. While morphologically-based methods outperform BPE in a few cases, what performs best tends to vary across tasks, and the performance of segmentation methods is often statistically indistinguishable.