 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoNLL#: Fine-grained Error Analysis and a Corrected Test Set for CoNLL-03 English
May 20, 2024Modern named entity recognition systems have steadily improved performance in the age of larger and more powerful neural models. However, over the past several years, the state-of-the-art has seemingly hit another plateau on the benchmark CoNLL-03 English dataset. In this paper, we perform a deep dive into the test outputs of the highest-performing NER models, conducting a fine-grained evaluation of their performance by introducing new document-level annotations on the test set. We go beyond F1 scores by categorizing errors in order to interpret the true state of the art for NER and guide future work. We review previous attempts at correcting the various flaws of the test set and introduce CoNLL#, a new corrected version of the test set that addresses its systematic and most prevalent errors, allowing for low-noise, interpretable error analysis.
* Accepted to LREC-COLING 2024
Overview of ADoBo 2021: Automatic Detection of Unassimilated Borrowings in the Spanish Press
Oct 29, 2021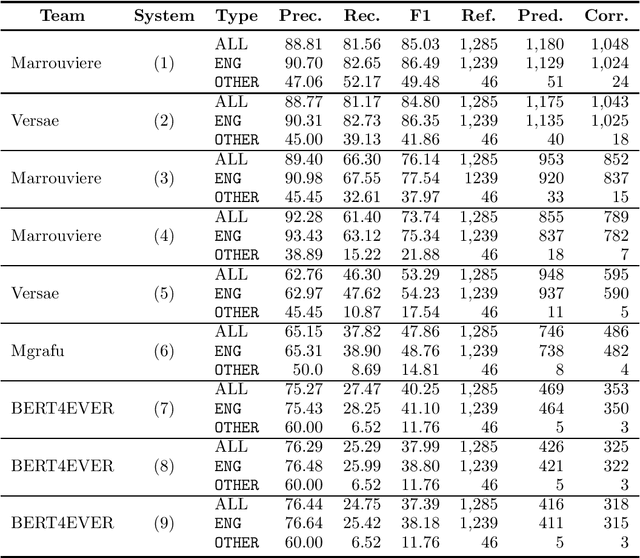
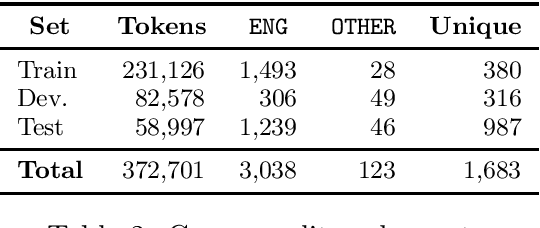
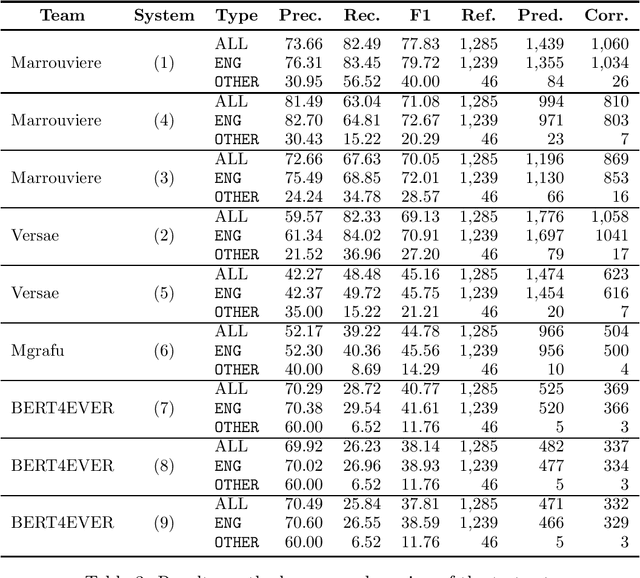
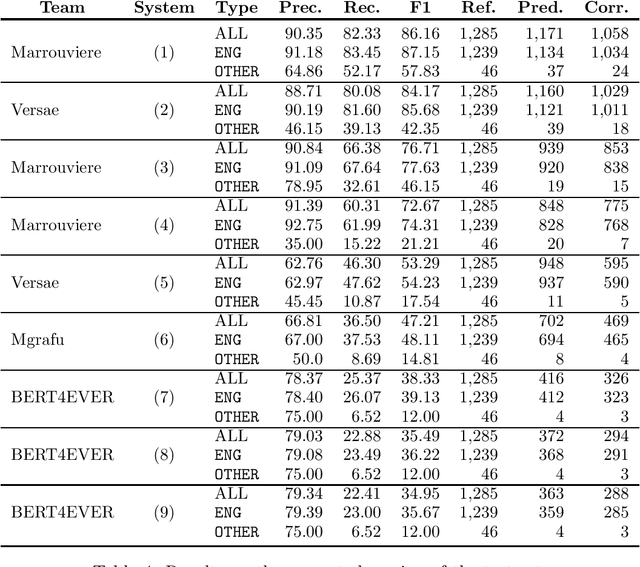
This paper summarizes the main findings of the ADoBo 2021 shared task, proposed in the context of IberLef 2021. In this task, we invited participants to detect lexical borrowings (coming mostly from English) in Spanish newswire texts. This task was framed as a sequence classification problem using BIO encoding. We provided participants with an annotated corpus of lexical borrowings which we split into training, development and test splits. We received submissions from 4 teams with 9 different system runs overall. The results, which range from F1 scores of 37 to 85, suggest that this is a challenging task, especially when out-of-domain or OOV words are considered, and that traditional methods informed with lexicographic information would benefit from taking advantage of current NLP trends.
* Post-print. Original version at Procesamiento del Lenguaje Natural 67 (2021), p. 277-285