 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBorrowing or Codeswitching? Annotating for Finer-Grained Distinctions in Language Mixing
Jun 10, 2022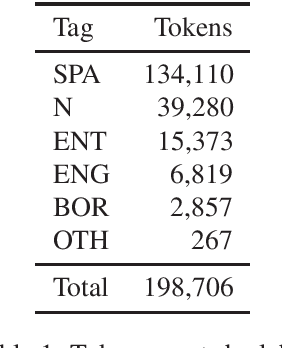
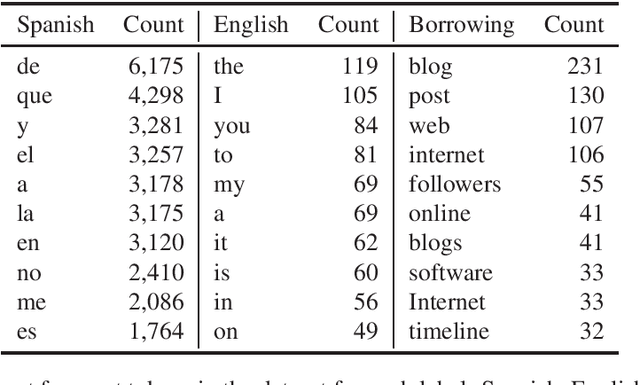

We present a new corpus of Twitter data annotated for codeswitching and borrowing between Spanish and English. The corpus contains 9,500 tweets annotated at the token level with codeswitches, borrowings, and named entities. This corpus differs from prior corpora of codeswitching in that we attempt to clearly define and annotate the boundary between codeswitching and borrowing and do not treat common "internet-speak" ('lol', etc.) as codeswitching when used in an otherwise monolingual context. The result is a corpus that enables the study and modeling of Spanish-English borrowing and codeswitching on Twitter in one dataset. We present baseline scores for modeling the labels of this corpus using Transformer-based language models. The annotation itself is released with a CC BY 4.0 license, while the text it applies to is distributed in compliance with the Twitter terms of service.