Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Machine Translation with Imbalanced Classes
Paper and Code
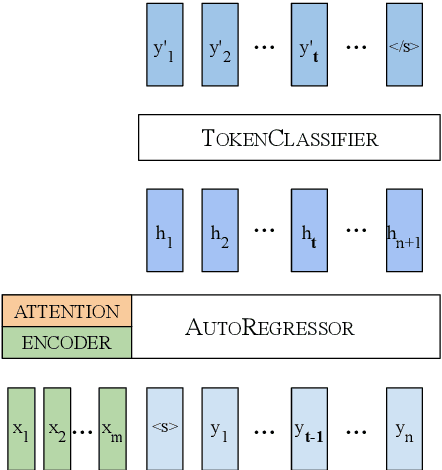

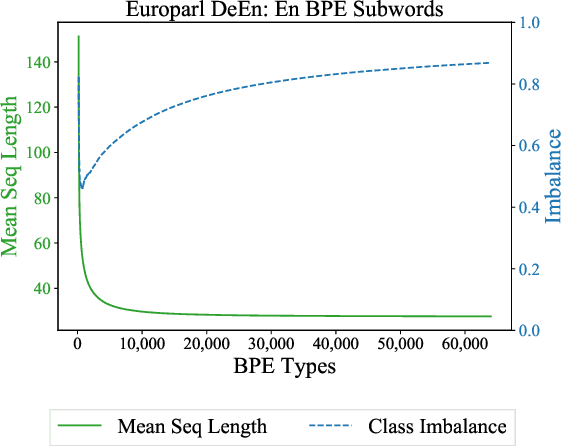
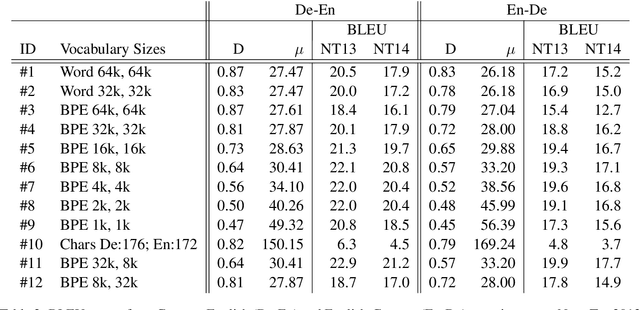
We cast neural machine translation (NMT) as a classification task in an autoregressive setting and analyze the limitations of both classification and autoregression components. Classifiers are known to perform better with balanced class distributions during training. Since the Zipfian nature of languages causes imbalanced classes, we explore the effect of class imbalance on NMT. We analyze the effect of vocabulary sizes on NMT performance and reveal an explanation for 'why' certain vocabulary sizes are better than others.
View paper on