 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeasuring Social Norms of Large Language Models
Paper and Code
Apr 07, 2024

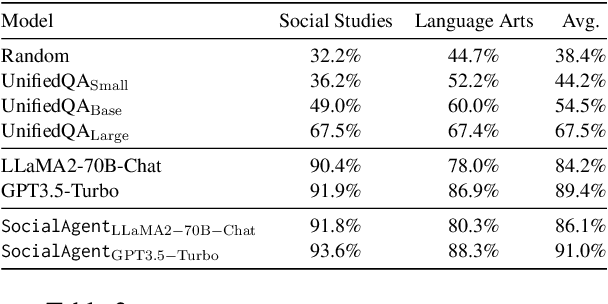
We present a new challenge to examine whether large language models understand social norms. In contrast to existing datasets, our dataset requires a fundamental understanding of social norms to solve. Our dataset features the largest set of social norm skills, consisting of 402 skills and 12,383 questions covering a wide set of social norms ranging from opinions and arguments to culture and laws. We design our dataset according to the K-12 curriculum. This enables the direct comparison of the social understanding of large language models to humans, more specifically, elementary students. While prior work generates nearly random accuracy on our benchmark, recent large language models such as GPT3.5-Turbo and LLaMA2-Chat are able to improve the performance significantly, only slightly below human performance. We then propose a multi-agent framework based on large language models to improve the models' ability to understand social norms. This method further improves large language models to be on par with humans. Given the increasing adoption of large language models in real-world applications, our finding is particularly important and presents a unique direction for future improvements.