 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSparse Hybrid Linear-Morphological Networks
Paper and Code
Apr 12, 2025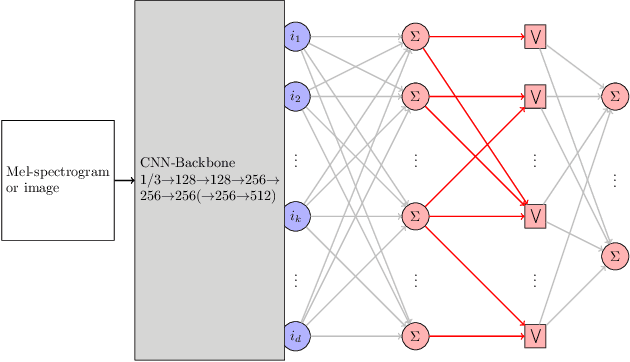
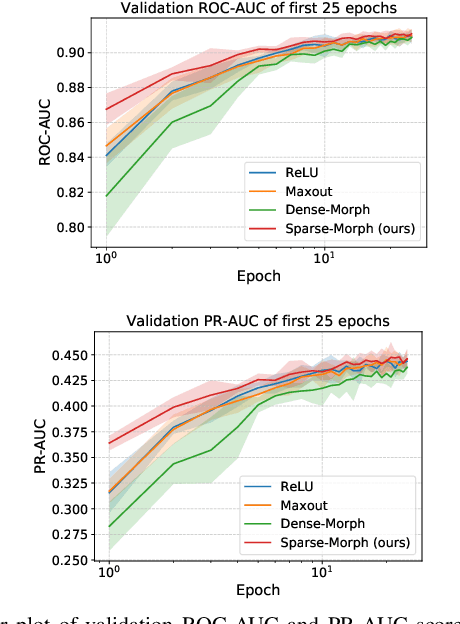
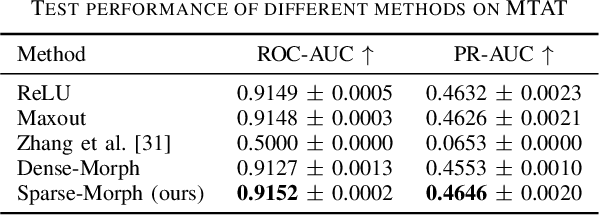

We investigate hybrid linear-morphological networks. Recent studies highlight the inherent affinity of morphological layers to pruning, but also their difficulty in training. We propose a hybrid network structure, wherein morphological layers are inserted between the linear layers of the network, in place of activation functions. We experiment with the following morphological layers: 1) maxout pooling layers (as a special case of a morphological layer), 2) fully connected dense morphological layers, and 3) a novel, sparsely initialized variant of (2). We conduct experiments on the Magna-Tag-A-Tune (music auto-tagging) and CIFAR-10 (image classification) datasets, replacing the linear classification heads of state-of-the-art convolutional network architectures with our proposed network structure for the various morphological layers. We demonstrate that these networks induce sparsity to their linear layers, making them more prunable under L1 unstructured pruning. We also show that on MTAT our proposed sparsely initialized layer achieves slightly better performance than ReLU, maxout, and densely initialized max-plus layers, and exhibits faster initial convergence.