 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHTMD-Net: A Hybrid Masking-Denoising Approach to Time-Domain Monaural Singing Voice Separation
Paper and Code
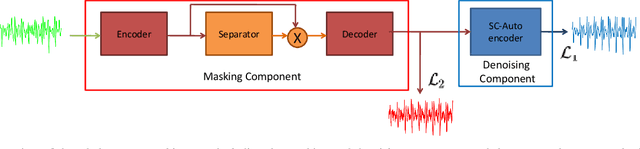
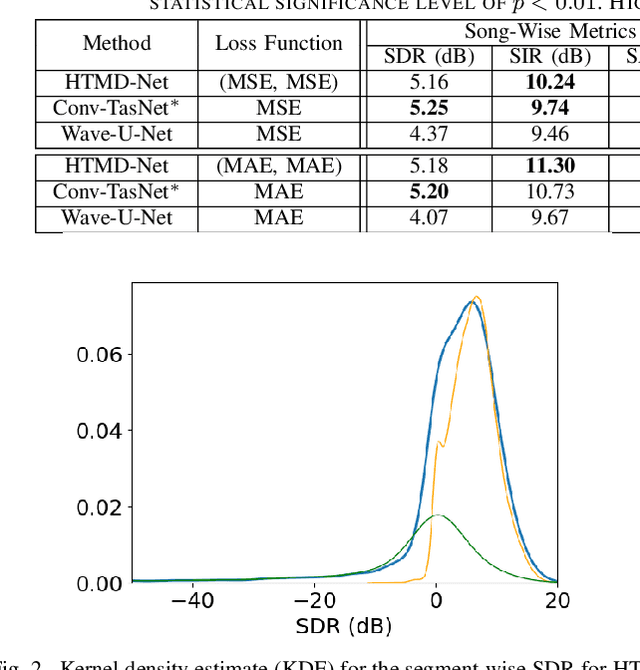
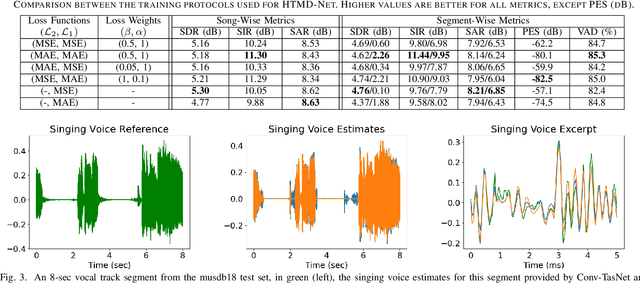

The advent of deep learning has led to the prevalence of deep neural network architectures for monaural music source separation, with end-to-end approaches that operate directly on the waveform level increasingly receiving research attention. Among these approaches, transformation of the input mixture to a learned latent space, and multiplicative application of a soft mask to the latent mixture, achieves the best performance, but is prone to the introduction of artifacts to the source estimate. To alleviate this problem, in this paper we propose a hybrid time-domain approach, termed the HTMD-Net, combining a lightweight masking component and a denoising module, based on skip connections, in order to refine the source estimated by the masking procedure. Evaluation of our approach in the task of monaural singing voice separation in the musdb18 dataset indicates that our proposed method achieves competitive performance compared to methods based purely on masking when trained under the same conditions, especially regarding the behavior during silent segments, while achieving higher computational efficiency.