 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeViDaS Video Depth-aware Saliency Network
May 19, 2023
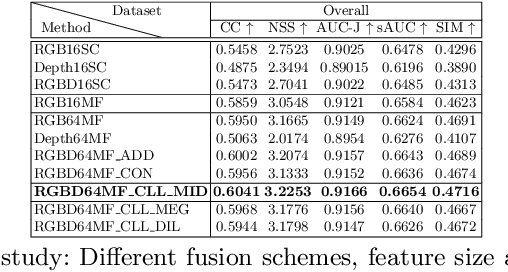
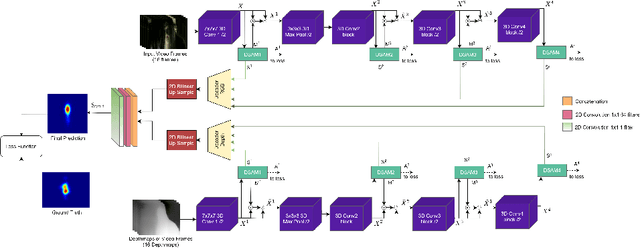

We introduce ViDaS, a two-stream, fully convolutional Video, Depth-Aware Saliency network to address the problem of attention modeling ``in-the-wild", via saliency prediction in videos. Contrary to existing visual saliency approaches using only RGB frames as input, our network employs also depth as an additional modality. The network consists of two visual streams, one for the RGB frames, and one for the depth frames. Both streams follow an encoder-decoder approach and are fused to obtain a final saliency map. The network is trained end-to-end and is evaluated in a variety of different databases with eye-tracking data, containing a wide range of video content. Although the publicly available datasets do not contain depth, we estimate it using three different state-of-the-art methods, to enable comparisons and a deeper insight. Our method outperforms in most cases state-of-the-art models and our RGB-only variant, which indicates that depth can be beneficial to accurately estimating saliency in videos displayed on a 2D screen. Depth has been widely used to assist salient object detection problems, where it has been proven to be very beneficial. Our problem though differs significantly from salient object detection, since it is not restricted to specific salient objects, but predicts human attention in a more general aspect. These two problems not only have different objectives, but also different ground truth data and evaluation metrics. To our best knowledge, this is the first competitive deep learning video saliency estimation approach that combines both RGB and Depth features to address the general problem of saliency estimation ``in-the-wild". The code will be publicly released.