 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeViDaS Video Depth-aware Saliency Network
May 19, 2023
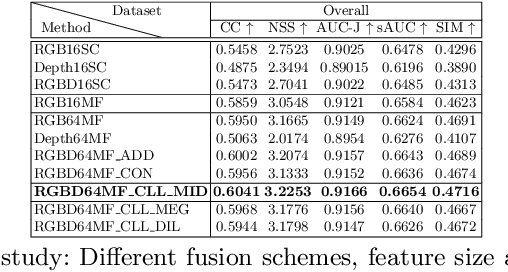
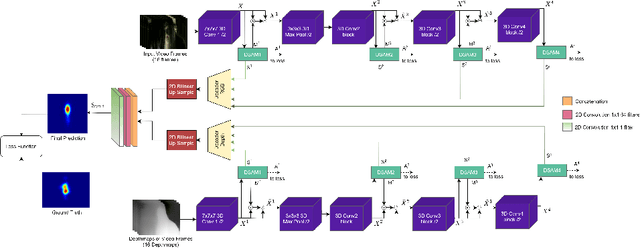

We introduce ViDaS, a two-stream, fully convolutional Video, Depth-Aware Saliency network to address the problem of attention modeling ``in-the-wild", via saliency prediction in videos. Contrary to existing visual saliency approaches using only RGB frames as input, our network employs also depth as an additional modality. The network consists of two visual streams, one for the RGB frames, and one for the depth frames. Both streams follow an encoder-decoder approach and are fused to obtain a final saliency map. The network is trained end-to-end and is evaluated in a variety of different databases with eye-tracking data, containing a wide range of video content. Although the publicly available datasets do not contain depth, we estimate it using three different state-of-the-art methods, to enable comparisons and a deeper insight. Our method outperforms in most cases state-of-the-art models and our RGB-only variant, which indicates that depth can be beneficial to accurately estimating saliency in videos displayed on a 2D screen. Depth has been widely used to assist salient object detection problems, where it has been proven to be very beneficial. Our problem though differs significantly from salient object detection, since it is not restricted to specific salient objects, but predicts human attention in a more general aspect. These two problems not only have different objectives, but also different ground truth data and evaluation metrics. To our best knowledge, this is the first competitive deep learning video saliency estimation approach that combines both RGB and Depth features to address the general problem of saliency estimation ``in-the-wild". The code will be publicly released.
ChildBot: Multi-Robot Perception and Interaction with Children
Aug 28, 2020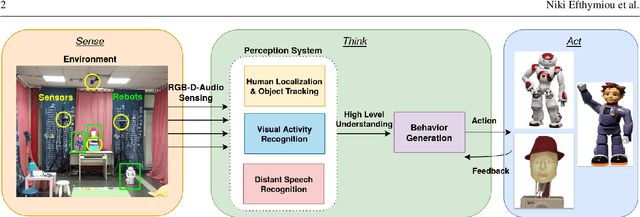

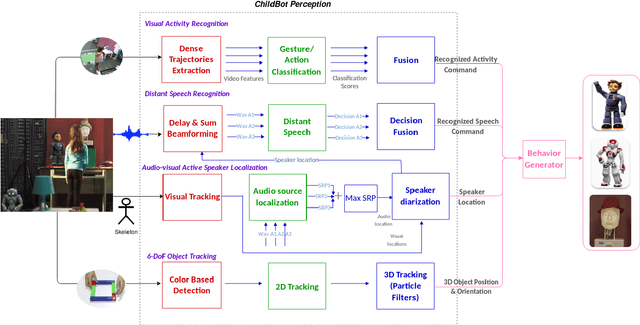
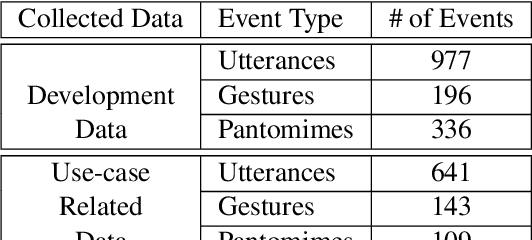
In this paper we present an integrated robotic system capable of participating in and performing a wide range of educational and entertainment tasks, in collaboration with one or more children. The system, called ChildBot, features multimodal perception modules and multiple robotic agents that monitor the interaction environment, and can robustly coordinate complex Child-Robot Interaction use-cases. In order to validate the effectiveness of the system and its integrated modules, we have conducted multiple experiments with a total of 52 children. Our results show improved perception capabilities in comparison to our earlier works that ChildBot was based on. In addition, we have conducted a preliminary user experience study, employing some educational/entertainment tasks, that yields encouraging results regarding the technical validity of our system and initial insights on the user experience with it.
STAViS: Spatio-Temporal AudioVisual Saliency Network
Jan 09, 2020


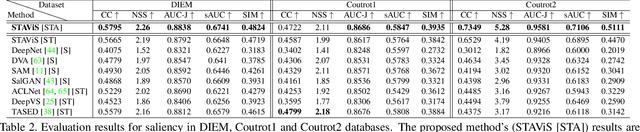
We introduce STAViS, a spatio-temporal audiovisual saliency network that combines spatio-temporal visual and auditory information in order to efficiently address the problem of saliency estimation in videos. Our approach employs a single network that combines visual saliency and auditory features and learns to appropriately localize sound sources and to fuse the two saliencies in order to obtain a final saliency map. The network has been designed, trained end-to-end, and evaluated on six different databases that contain audiovisual eye-tracking data of a large variety of videos. We compare our method against 8 different state-of-the-art visual saliency models. Evaluation results across databases indicate that our STAViS model outperforms our visual only variant as well as the other state-of-the-art models in the majority of cases. Also, the consistently good performance it achieves for all databases indicates that it is appropriate for estimating saliency "in-the-wild".