 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Transcript-assisted Video Summarization and Highlight Detection
May 29, 2025Video consumption is a key part of daily life, but watching entire videos can be tedious. To address this, researchers have explored video summarization and highlight detection to identify key video segments. While some works combine video frames and transcripts, and others tackle video summarization and highlight detection using Reinforcement Learning (RL), no existing work, to the best of our knowledge, integrates both modalities within an RL framework. In this paper, we propose a multimodal pipeline that leverages video frames and their corresponding transcripts to generate a more condensed version of the video and detect highlights using a modality fusion mechanism. The pipeline is trained within an RL framework, which rewards the model for generating diverse and representative summaries while ensuring the inclusion of video segments with meaningful transcript content. The unsupervised nature of the training allows for learning from large-scale unannotated datasets, overcoming the challenge posed by the limited size of existing annotated datasets. Our experiments show that using the transcript in video summarization and highlight detection achieves superior results compared to relying solely on the visual content of the video.
Emotion Understanding in Videos Through Body, Context, and Visual-Semantic Embedding Loss
Oct 30, 2020We present our winning submission to the First International Workshop on Bodily Expressed Emotion Understanding (BEEU) challenge. Based on recent literature on the effect of context/environment on emotion, as well as visual representations with semantic meaning using word embeddings, we extend the framework of Temporal Segment Network to accommodate these. Our method is verified on the validation set of the Body Language Dataset (BoLD) and achieves 0.26235 Emotion Recognition Score on the test set, surpassing the previous best result of 0.2530.
ChildBot: Multi-Robot Perception and Interaction with Children
Aug 28, 2020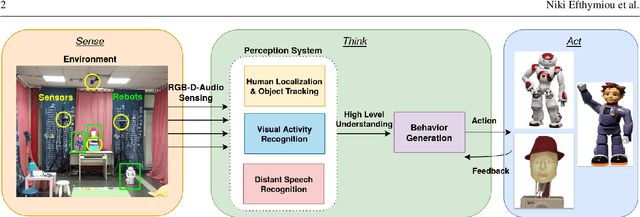

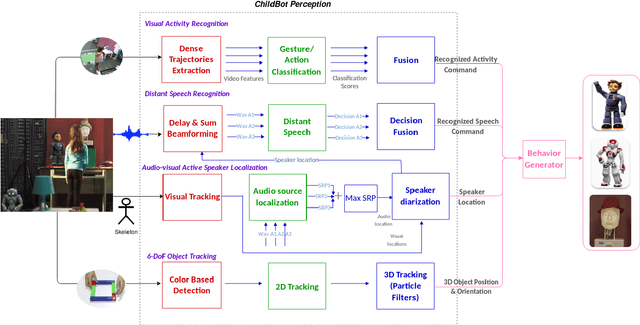
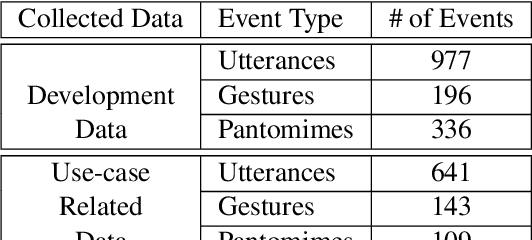
In this paper we present an integrated robotic system capable of participating in and performing a wide range of educational and entertainment tasks, in collaboration with one or more children. The system, called ChildBot, features multimodal perception modules and multiple robotic agents that monitor the interaction environment, and can robustly coordinate complex Child-Robot Interaction use-cases. In order to validate the effectiveness of the system and its integrated modules, we have conducted multiple experiments with a total of 52 children. Our results show improved perception capabilities in comparison to our earlier works that ChildBot was based on. In addition, we have conducted a preliminary user experience study, employing some educational/entertainment tasks, that yields encouraging results regarding the technical validity of our system and initial insights on the user experience with it.
A Deep Learning Approach to Object Affordance Segmentation
Apr 18, 2020

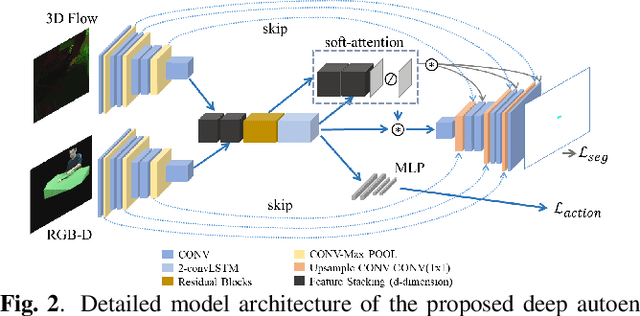

Learning to understand and infer object functionalities is an important step towards robust visual intelligence. Significant research efforts have recently focused on segmenting the object parts that enable specific types of human-object interaction, the so-called "object affordances". However, most works treat it as a static semantic segmentation problem, focusing solely on object appearance and relying on strong supervision and object detection. In this paper, we propose a novel approach that exploits the spatio-temporal nature of human-object interaction for affordance segmentation. In particular, we design an autoencoder that is trained using ground-truth labels of only the last frame of the sequence, and is able to infer pixel-wise affordance labels in both videos and static images. Our model surpasses the need for object labels and bounding boxes by using a soft-attention mechanism that enables the implicit localization of the interaction hotspot. For evaluation purposes, we introduce the SOR3D-AFF corpus, which consists of human-object interaction sequences and supports 9 types of affordances in terms of pixel-wise annotation, covering typical manipulations of tool-like objects. We show that our model achieves competitive results compared to strongly supervised methods on SOR3D-AFF, while being able to predict affordances for similar unseen objects in two affordance image-only datasets.
Fusing Body Posture with Facial Expressions for Joint Recognition of Affect in Child-Robot Interaction
Jan 07, 2019
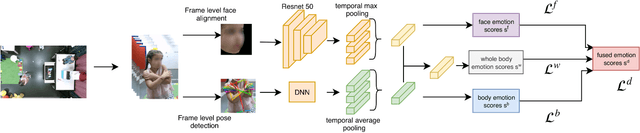

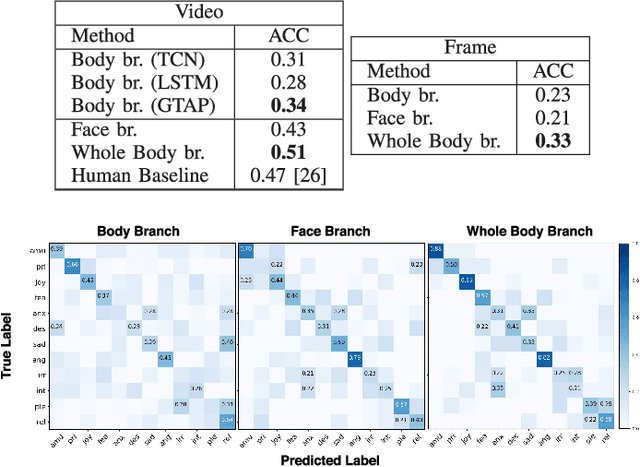
In this paper we address the problem of multi-cue affect recognition in challenging environments such as child-robot interaction. Towards this goal we propose a method for automatic recognition of affect that leverages body expressions alongside facial expressions, as opposed to traditional methods that usually focus only on the latter. We evaluate our methods on a challenging child-robot interaction database of emotional expressions, as well as on a database of emotional expressions by actors, and show that the proposed method achieves significantly better results when compared with the facial expression baselines, can be trained both jointly and separately, and offers us computational models for both the individual modalities, as well as for the whole body emotion.
Deep Affordance-grounded Sensorimotor Object Recognition
Apr 10, 2017



It is well-established by cognitive neuroscience that human perception of objects constitutes a complex process, where object appearance information is combined with evidence about the so-called object "affordances", namely the types of actions that humans typically perform when interacting with them. This fact has recently motivated the "sensorimotor" approach to the challenging task of automatic object recognition, where both information sources are fused to improve robustness. In this work, the aforementioned paradigm is adopted, surpassing current limitations of sensorimotor object recognition research. Specifically, the deep learning paradigm is introduced to the problem for the first time, developing a number of novel neuro-biologically and neuro-physiologically inspired architectures that utilize state-of-the-art neural networks for fusing the available information sources in multiple ways. The proposed methods are evaluated using a large RGB-D corpus, which is specifically collected for the task of sensorimotor object recognition and is made publicly available. Experimental results demonstrate the utility of affordance information to object recognition, achieving an up to 29% relative error reduction by its inclusion.