 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMind the Shape Gap: A Benchmark and Baseline for Deformation-Aware 6D Pose Estimation of Agricultural Produce
Mar 28, 2026Accurate 6D pose estimation for robotic harvesting is fundamentally hindered by the biological deformability and high intra-class shape variability of agricultural produce. Instance-level methods fail in this setting, as obtaining exact 3D models for every unique piece of produce is practically infeasible, while category-level approaches that rely on a fixed template suffer significant accuracy degradation when the prior deviates from the true instance geometry. To bridge such lack of robustness to deformation, we introduce PEAR (Pose and dEformation of Agricultural pRoduce), the first benchmark providing joint 6D pose and per-instance 3D deformation ground truth across 8 produce categories, acquired via a robotic manipulator for high annotation accuracy. Using PEAR, we show that state-of-the-art methods suffer up to 6x performance degradation when faced with the inherent geometric deviations of real-world produce. Motivated by this finding, we propose SEED (Simultaneous Estimation of posE and Deformation), a unified RGB-only framework that jointly predicts 6D pose and explicit lattice deformations from a single image across multiple produce categories. Trained entirely on synthetic data with generative texture augmentation applied at the UV level, SEED outperforms MegaPose on 6 out of 8 categories under identical RGB-only conditions, demonstrating that explicit shape modeling is a critical step toward reliable pose estimation in agricultural robotics.
Baby Sophia: A Developmental Approach to Self-Exploration through Self-Touch and Hand Regard
Nov 12, 2025Inspired by infant development, we propose a Reinforcement Learning (RL) framework for autonomous self-exploration in a robotic agent, Baby Sophia, using the BabyBench simulation environment. The agent learns self-touch and hand regard behaviors through intrinsic rewards that mimic an infant's curiosity-driven exploration of its own body. For self-touch, high-dimensional tactile inputs are transformed into compact, meaningful representations, enabling efficient learning. The agent then discovers new tactile contacts through intrinsic rewards and curriculum learning that encourage broad body coverage, balance, and generalization. For hand regard, visual features of the hands, such as skin-color and shape, are learned through motor babbling. Then, intrinsic rewards encourage the agent to perform novel hand motions, and follow its hands with its gaze. A curriculum learning setup from single-hand to dual-hand training allows the agent to reach complex visual-motor coordination. The results of this work demonstrate that purely curiosity-based signals, with no external supervision, can drive coordinated multimodal learning, imitating an infant's progression from random motor babbling to purposeful behaviors.
Mushroom Segmentation and 3D Pose Estimation from Point Clouds using Fully Convolutional Geometric Features and Implicit Pose Encoding
Apr 17, 2024



Modern agricultural applications rely more and more on deep learning solutions. However, training well-performing deep networks requires a large amount of annotated data that may not be available and in the case of 3D annotation may not even be feasible for human annotators. In this work, we develop a deep learning approach to segment mushrooms and estimate their pose on 3D data, in the form of point clouds acquired by depth sensors. To circumvent the annotation problem, we create a synthetic dataset of mushroom scenes, where we are fully aware of 3D information, such as the pose of each mushroom. The proposed network has a fully convolutional backbone, that parses sparse 3D data, and predicts pose information that implicitly defines both instance segmentation and pose estimation task. We have validated the effectiveness of the proposed implicit-based approach for a synthetic test set, as well as provided qualitative results for a small set of real acquired point clouds with depth sensors. Code is publicly available at https://github.com/georgeretsi/mushroom-pose.
Emotion Understanding in Videos Through Body, Context, and Visual-Semantic Embedding Loss
Oct 30, 2020We present our winning submission to the First International Workshop on Bodily Expressed Emotion Understanding (BEEU) challenge. Based on recent literature on the effect of context/environment on emotion, as well as visual representations with semantic meaning using word embeddings, we extend the framework of Temporal Segment Network to accommodate these. Our method is verified on the validation set of the Body Language Dataset (BoLD) and achieves 0.26235 Emotion Recognition Score on the test set, surpassing the previous best result of 0.2530.
ChildBot: Multi-Robot Perception and Interaction with Children
Aug 28, 2020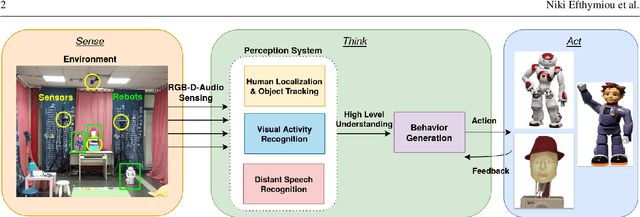

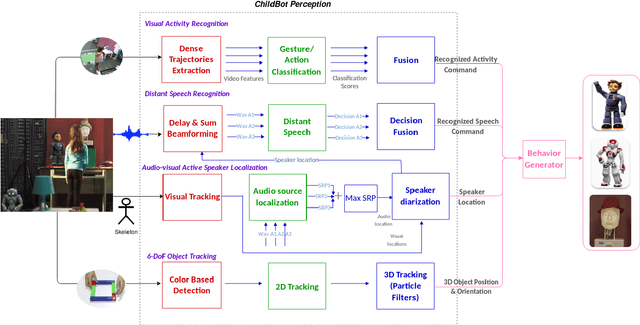
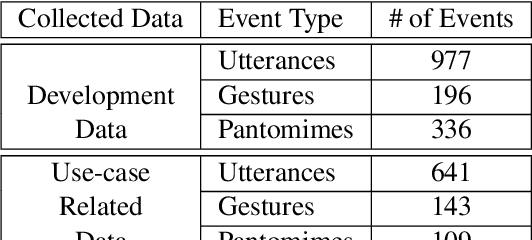
In this paper we present an integrated robotic system capable of participating in and performing a wide range of educational and entertainment tasks, in collaboration with one or more children. The system, called ChildBot, features multimodal perception modules and multiple robotic agents that monitor the interaction environment, and can robustly coordinate complex Child-Robot Interaction use-cases. In order to validate the effectiveness of the system and its integrated modules, we have conducted multiple experiments with a total of 52 children. Our results show improved perception capabilities in comparison to our earlier works that ChildBot was based on. In addition, we have conducted a preliminary user experience study, employing some educational/entertainment tasks, that yields encouraging results regarding the technical validity of our system and initial insights on the user experience with it.
Fusing Body Posture with Facial Expressions for Joint Recognition of Affect in Child-Robot Interaction
Jan 07, 2019
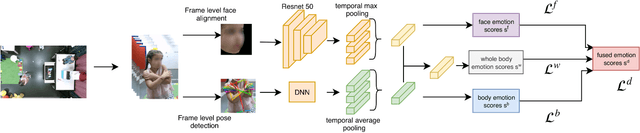

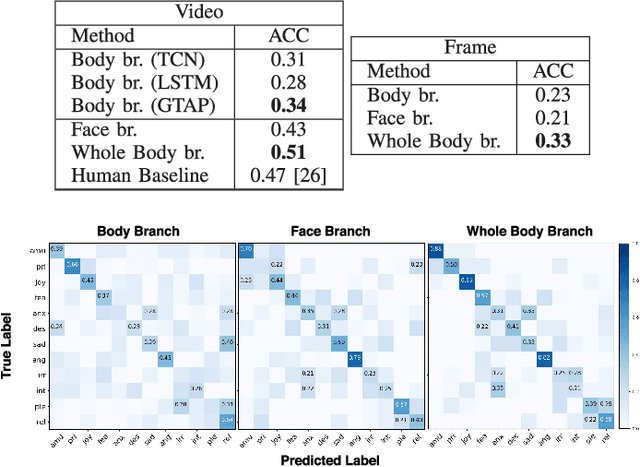
In this paper we address the problem of multi-cue affect recognition in challenging environments such as child-robot interaction. Towards this goal we propose a method for automatic recognition of affect that leverages body expressions alongside facial expressions, as opposed to traditional methods that usually focus only on the latter. We evaluate our methods on a challenging child-robot interaction database of emotional expressions, as well as on a database of emotional expressions by actors, and show that the proposed method achieves significantly better results when compared with the facial expression baselines, can be trained both jointly and separately, and offers us computational models for both the individual modalities, as well as for the whole body emotion.