 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSTAViS: Spatio-Temporal AudioVisual Saliency Network
Paper and Code



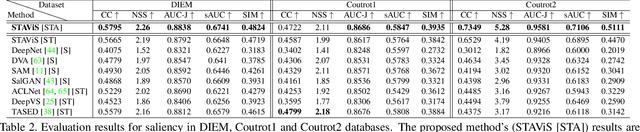
We introduce STAViS, a spatio-temporal audiovisual saliency network that combines spatio-temporal visual and auditory information in order to efficiently address the problem of saliency estimation in videos. Our approach employs a single network that combines visual saliency and auditory features and learns to appropriately localize sound sources and to fuse the two saliencies in order to obtain a final saliency map. The network has been designed, trained end-to-end, and evaluated on six different databases that contain audiovisual eye-tracking data of a large variety of videos. We compare our method against 8 different state-of-the-art visual saliency models. Evaluation results across databases indicate that our STAViS model outperforms our visual only variant as well as the other state-of-the-art models in the majority of cases. Also, the consistently good performance it achieves for all databases indicates that it is appropriate for estimating saliency "in-the-wild".