 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3D-OES: Viewpoint-Invariant Object-Factorized Environment Simulators
Paper and Code
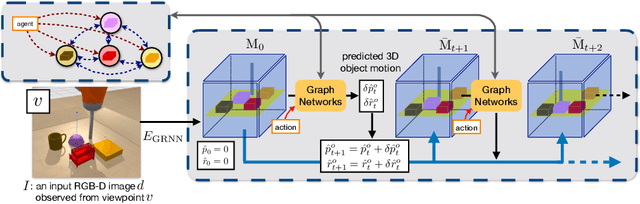


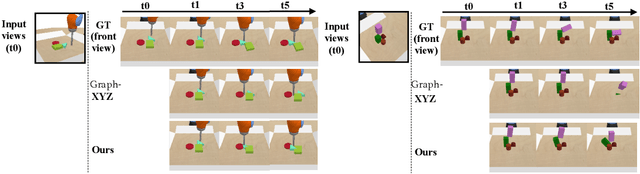
We propose an action-conditioned dynamics model that predicts scene changes caused by object and agent interactions in a viewpoint-invariant 3D neural scene representation space, inferred from RGB-D videos. In this 3D feature space, objects do not interfere with one another and their appearance persists over time and across viewpoints. This permits our model to predict future scenes long in the future by simply "moving" 3D object features based on cumulative object motion predictions. Object motion predictions are computed by a graph neural network that operates over the object features extracted from the 3D neural scene representation. Our model's simulations can be decoded by a neural renderer into2D image views from any desired viewpoint, which aids the interpretability of our latent 3D simulation space. We show our model generalizes well its predictions across varying number and appearances of interacting objects as well as across camera viewpoints, outperforming existing 2D and 3D dynamics models. We further demonstrate sim-to-real transfer of the learnt dynamics by applying our model trained solely in simulation to model-based control for pushing objects to desired locations under clutter on a real robotic setup