 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHigh-Fidelity and Long-Duration Human Image Animation with Diffusion Transformer
Dec 26, 2025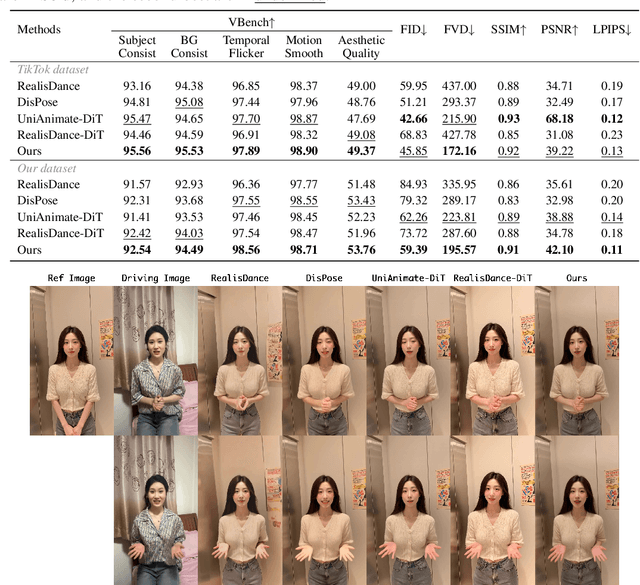

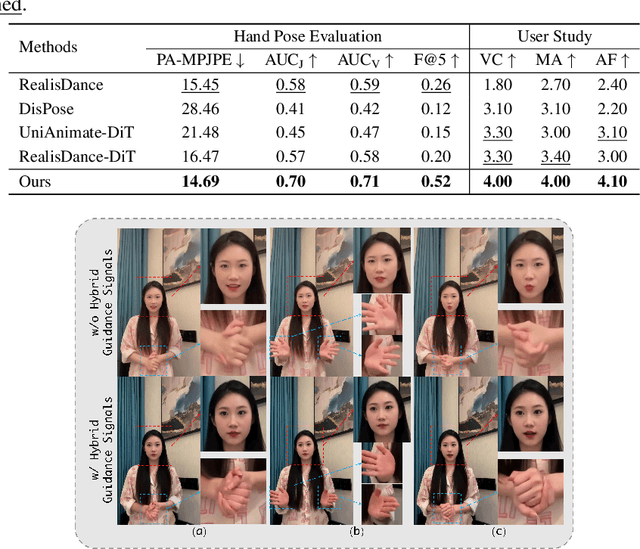
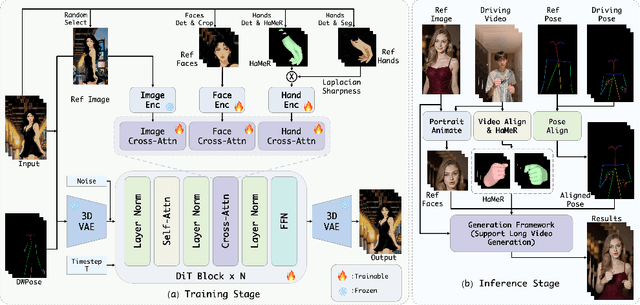
Recent progress in diffusion models has significantly advanced the field of human image animation. While existing methods can generate temporally consistent results for short or regular motions, significant challenges remain, particularly in generating long-duration videos. Furthermore, the synthesis of fine-grained facial and hand details remains under-explored, limiting the applicability of current approaches in real-world, high-quality applications. To address these limitations, we propose a diffusion transformer (DiT)-based framework which focuses on generating high-fidelity and long-duration human animation videos. First, we design a set of hybrid implicit guidance signals and a sharpness guidance factor, enabling our framework to additionally incorporate detailed facial and hand features as guidance. Next, we incorporate the time-aware position shift fusion module, modify the input format within the DiT backbone, and refer to this mechanism as the Position Shift Adaptive Module, which enables video generation of arbitrary length. Finally, we introduce a novel data augmentation strategy and a skeleton alignment model to reduce the impact of human shape variations across different identities. Experimental results demonstrate that our method outperforms existing state-of-the-art approaches, achieving superior performance in both high-fidelity and long-duration human image animation.
Playmate: Flexible Control of Portrait Animation via 3D-Implicit Space Guided Diffusion
Feb 11, 2025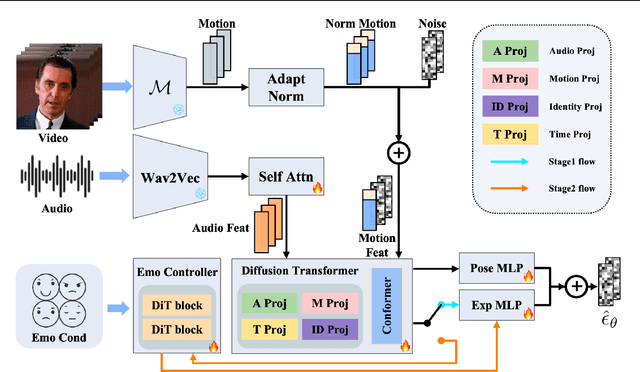



Recent diffusion-based talking face generation models have demonstrated impressive potential in synthesizing videos that accurately match a speech audio clip with a given reference identity. However, existing approaches still encounter significant challenges due to uncontrollable factors, such as inaccurate lip-sync, inappropriate head posture and the lack of fine-grained control over facial expressions. In order to introduce more face-guided conditions beyond speech audio clips, a novel two-stage training framework Playmate is proposed to generate more lifelike facial expressions and talking faces. In the first stage, we introduce a decoupled implicit 3D representation along with a meticulously designed motion-decoupled module to facilitate more accurate attribute disentanglement and generate expressive talking videos directly from audio cues. Then, in the second stage, we introduce an emotion-control module to encode emotion control information into the latent space, enabling fine-grained control over emotions and thereby achieving the ability to generate talking videos with desired emotion. Extensive experiments demonstrate that Playmate outperforms existing state-of-the-art methods in terms of video quality and lip-synchronization, and improves flexibility in controlling emotion and head pose. The code will be available at https://playmate111.github.io.
TMGAN-PLC: Audio Packet Loss Concealment using Temporal Memory Generative Adversarial Network
Jul 04, 2022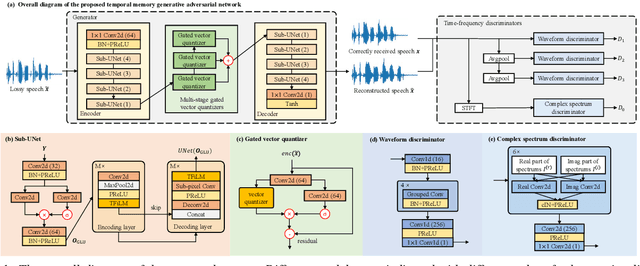
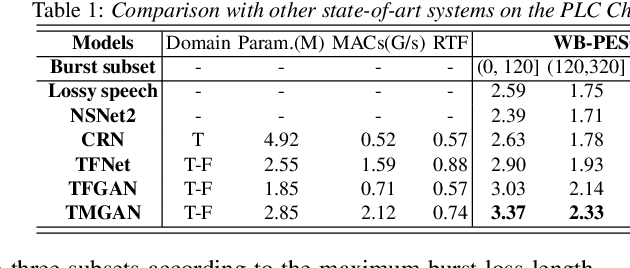
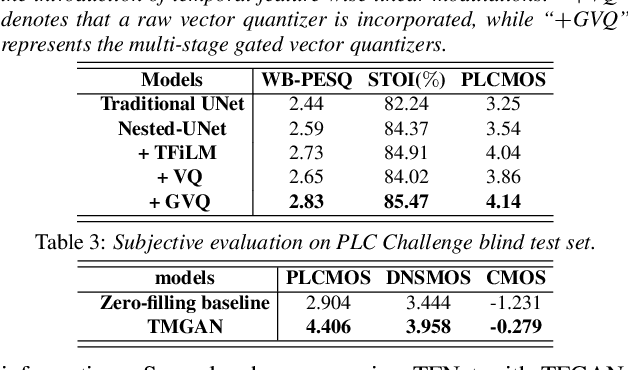
Real-time communications in packet-switched networks have become widely used in daily communication, while they inevitably suffer from network delays and data losses in constrained real-time conditions. To solve these problems, audio packet loss concealment (PLC) algorithms have been developed to mitigate voice transmission failures by reconstructing the lost information. Limited by the transmission latency and device memory, it is still intractable for PLC to accomplish high-quality voice reconstruction using a relatively small packet buffer. In this paper, we propose a temporal memory generative adversarial network for audio PLC, dubbed TMGAN-PLC, which is comprised of a novel nested-UNet generator and the time-domain/frequency-domain discriminators. Specifically, a combination of the nested-UNet and temporal feature-wise linear modulation is elaborately devised in the generator to finely adjust the intra-frame information and establish inter-frame temporal dependencies. To complement the missing speech content caused by longer loss bursts, we employ multi-stage gated vector quantizers to capture the correct content and reconstruct the near-real smooth audio. Extensive experiments on the PLC Challenge dataset demonstrate that the proposed method yields promising performance in terms of speech quality, intelligibility, and PLCMOS.
DMF-Net: A decoupling-style multi-band fusion model for real-time full-band speech enhancement
Mar 02, 2022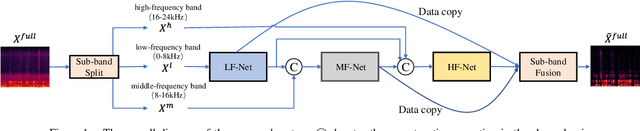
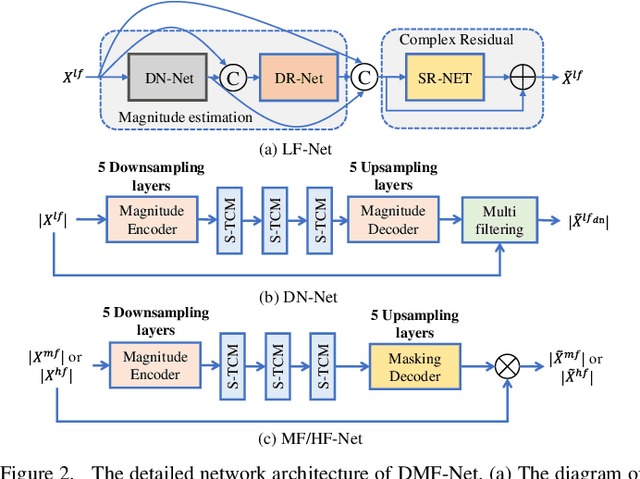
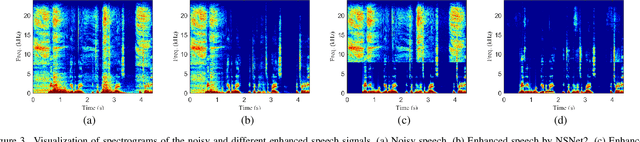
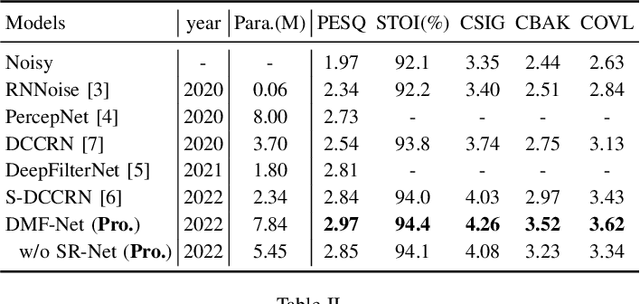
Full-band speech enhancement based on deep neural networks is still challenging for the difficulty of modeling more frequency bands and real-time implementation. Previous studies usually adopt compressed full-band speech features in Bark and ERB scale with relatively low frequency resolution, leading to degraded performance, especially in the high-frequency region. In this paper, we propose a decoupling-style multi-band fusion model to perform full-band speech denoising and dereverberation. Instead of optimizing the full-band speech by a single network structure, we decompose the full-band target into multi sub bands and then employ a multi-stage chain optimization strategy to estimate clean spectrum stage by stage. Specifically, the low- (0-8 kHz), middle- (8-16 kHz), and high-frequency (16-24 kHz) regions are mapped by three separate sub-networks and are then fused to obtain the full-band clean target STFT spectrum. Comprehensive experiments on two public datasets demonstrate that the proposed method outperforms previous advanced systems and yields promising performance in terms of speech quality and intelligibility in real complex scenarios.