 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDMF-Net: A decoupling-style multi-band fusion model for real-time full-band speech enhancement
Mar 02, 2022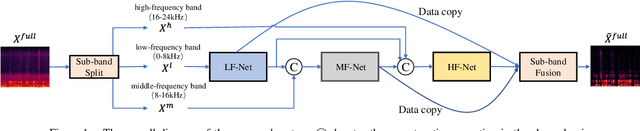
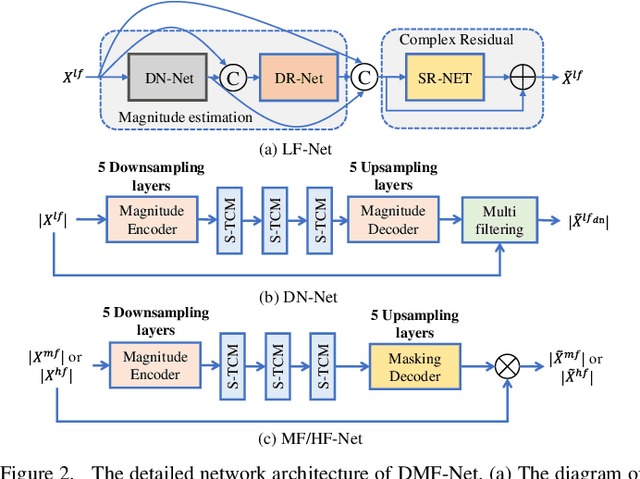
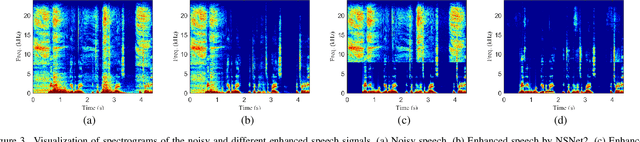
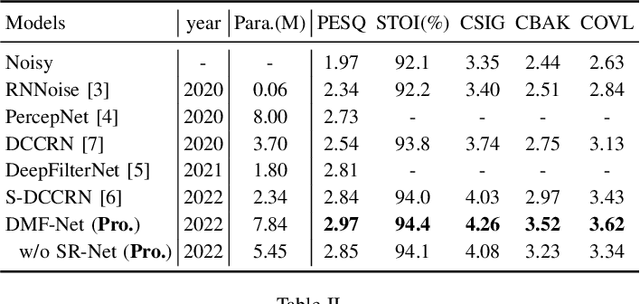
Full-band speech enhancement based on deep neural networks is still challenging for the difficulty of modeling more frequency bands and real-time implementation. Previous studies usually adopt compressed full-band speech features in Bark and ERB scale with relatively low frequency resolution, leading to degraded performance, especially in the high-frequency region. In this paper, we propose a decoupling-style multi-band fusion model to perform full-band speech denoising and dereverberation. Instead of optimizing the full-band speech by a single network structure, we decompose the full-band target into multi sub bands and then employ a multi-stage chain optimization strategy to estimate clean spectrum stage by stage. Specifically, the low- (0-8 kHz), middle- (8-16 kHz), and high-frequency (16-24 kHz) regions are mapped by three separate sub-networks and are then fused to obtain the full-band clean target STFT spectrum. Comprehensive experiments on two public datasets demonstrate that the proposed method outperforms previous advanced systems and yields promising performance in terms of speech quality and intelligibility in real complex scenarios.
A Robust Maximum Likelihood Distortionless Response Beamformer based on a Complex Generalized Gaussian Distribution
Feb 19, 2021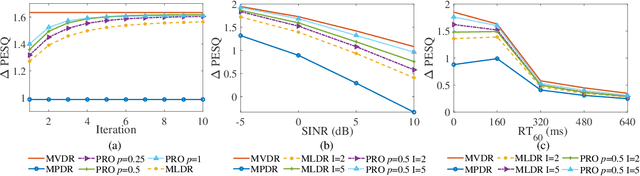
For multichannel speech enhancement, this letter derives a robust maximum likelihood distortionless response beamformer by modeling speech sparse priors with a complex generalized Gaussian distribution, where we refer to as the CGGD-MLDR beamformer. The proposed beamformer can be regarded as a generalization of the minimum power distortionless response beamformer and its improved variations. For narrowband applications, we also reveal that the proposed beamformer reduces to the minimum dispersion distortionless response beamformer, which has been derived with the ${{\ell}_{p}}$-norm minimization. The mechanisms of the proposed beamformer in improving the robustness are clearly pointed out and experimental results show its better performance in PESQ improvement.