 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTMGAN-PLC: Audio Packet Loss Concealment using Temporal Memory Generative Adversarial Network
Paper and Code
Jul 04, 2022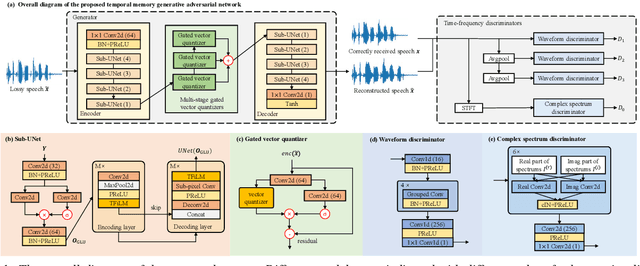
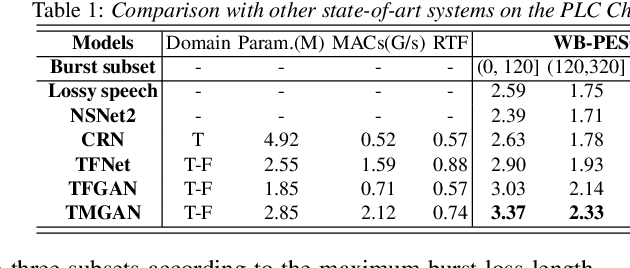
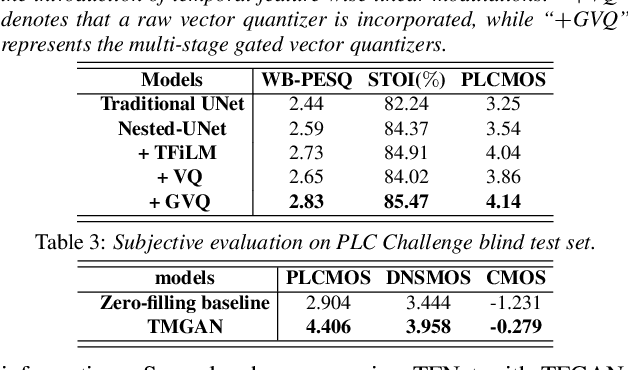
Real-time communications in packet-switched networks have become widely used in daily communication, while they inevitably suffer from network delays and data losses in constrained real-time conditions. To solve these problems, audio packet loss concealment (PLC) algorithms have been developed to mitigate voice transmission failures by reconstructing the lost information. Limited by the transmission latency and device memory, it is still intractable for PLC to accomplish high-quality voice reconstruction using a relatively small packet buffer. In this paper, we propose a temporal memory generative adversarial network for audio PLC, dubbed TMGAN-PLC, which is comprised of a novel nested-UNet generator and the time-domain/frequency-domain discriminators. Specifically, a combination of the nested-UNet and temporal feature-wise linear modulation is elaborately devised in the generator to finely adjust the intra-frame information and establish inter-frame temporal dependencies. To complement the missing speech content caused by longer loss bursts, we employ multi-stage gated vector quantizers to capture the correct content and reconstruct the near-real smooth audio. Extensive experiments on the PLC Challenge dataset demonstrate that the proposed method yields promising performance in terms of speech quality, intelligibility, and PLCMOS.