 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Interpretable Embeddings for Ad-hoc Video Search with Generative Captions and Multi-word Concept Bank
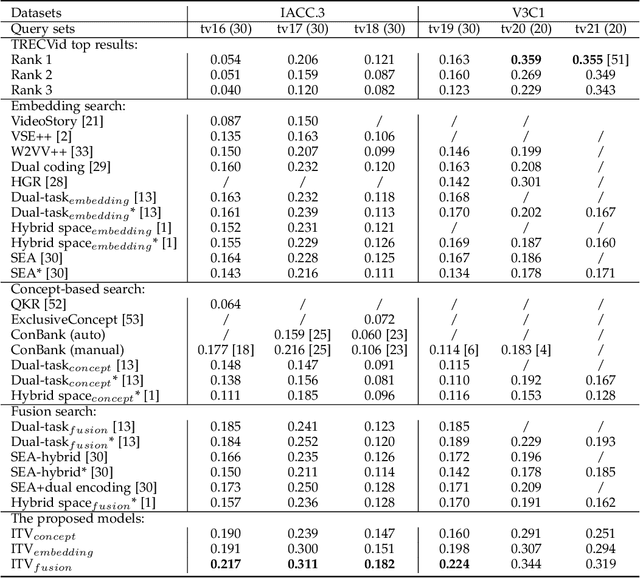
Apr 09, 2024Aligning a user query and video clips in cross-modal latent space and that with semantic concepts are two mainstream approaches for ad-hoc video search (AVS). However, the effectiveness of existing approaches is bottlenecked by the small sizes of available video-text datasets and the low quality of concept banks, which results in the failures of unseen queries and the out-of-vocabulary problem. This paper addresses these two problems by constructing a new dataset and developing a multi-word concept bank. Specifically, capitalizing on a generative model, we construct a new dataset consisting of 7 million generated text and video pairs for pre-training. To tackle the out-of-vocabulary problem, we develop a multi-word concept bank based on syntax analysis to enhance the capability of a state-of-the-art interpretable AVS method in modeling relationships between query words. We also study the impact of current advanced features on the method. Experimental results show that the integration of the above-proposed elements doubles the R@1 performance of the AVS method on the MSRVTT dataset and improves the xinfAP on the TRECVid AVS query sets for 2016-2023 (eight years) by a margin from 2% to 77%, with an average about 20%.
Incremental Learning on Food Instance Segmentation
Jun 28, 2023Food instance segmentation is essential to estimate the serving size of dishes in a food image. The recent cutting-edge techniques for instance segmentation are deep learning networks with impressive segmentation quality and fast computation. Nonetheless, they are hungry for data and expensive for annotation. This paper proposes an incremental learning framework to optimize the model performance given a limited data labelling budget. The power of the framework is a novel difficulty assessment model, which forecasts how challenging an unlabelled sample is to the latest trained instance segmentation model. The data collection procedure is divided into several stages, each in which a new sample package is collected. The framework allocates the labelling budget to the most difficult samples. The unlabelled samples that meet a certain qualification from the assessment model are used to generate pseudo-labels. Eventually, the manual labels and pseudo-labels are sent to the training data to improve the instance segmentation model. On four large-scale food datasets, our proposed framework outperforms current incremental learning benchmarks and achieves competitive performance with the model trained on fully annotated samples.
GroundNLQ @ Ego4D Natural Language Queries Challenge 2023
Jun 27, 2023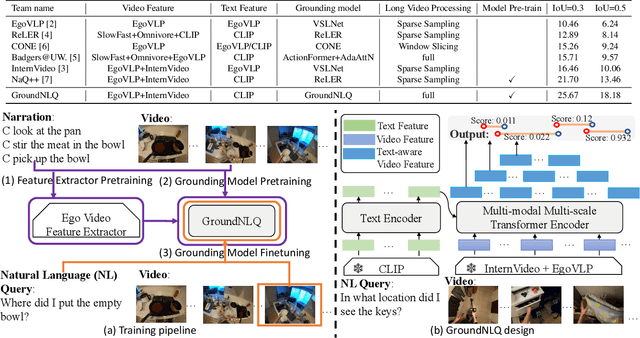
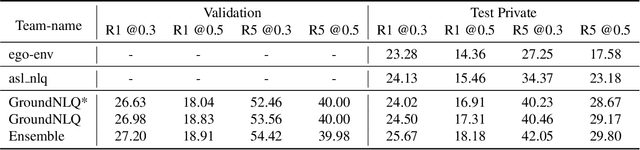

In this report, we present our champion solution for Ego4D Natural Language Queries (NLQ) Challenge in CVPR 2023. Essentially, to accurately ground in a video, an effective egocentric feature extractor and a powerful grounding model are required. Motivated by this, we leverage a two-stage pre-training strategy to train egocentric feature extractors and the grounding model on video narrations, and further fine-tune the model on annotated data. In addition, we introduce a novel grounding model GroundNLQ, which employs a multi-modal multi-scale grounding module for effective video and text fusion and various temporal intervals, especially for long videos. On the blind test set, GroundNLQ achieves 25.67 and 18.18 for R1@IoU=0.3 and R1@IoU=0.5, respectively, and surpasses all other teams by a noticeable margin. Our code will be released at\url{https://github.com/houzhijian/GroundNLQ}.
An Efficient COarse-to-fiNE Alignment Framework @ Ego4D Natural Language Queries Challenge 2022
Nov 16, 2022



This technical report describes the CONE approach for Ego4D Natural Language Queries (NLQ) Challenge in ECCV 2022. We leverage our model CONE, an efficient window-centric COarse-to-fiNE alignment framework. Specifically, CONE dynamically slices the long video into candidate windows via a sliding window approach. Centering at windows, CONE (1) learns the inter-window (coarse-grained) semantic variance through contrastive learning and speeds up inference by pre-filtering the candidate windows relevant to the NL query, and (2) conducts intra-window (fine-grained) candidate moments ranking utilizing the powerful multi-modal alignment ability of the contrastive vision-text pre-trained model EgoVLP. On the blind test set, CONE achieves 15.26 and 9.24 for R1@IoU=0.3 and R1@IoU=0.5, respectively.
CONE: An Efficient COarse-to-fiNE Alignment Framework for Long Video Temporal Grounding
Sep 22, 2022

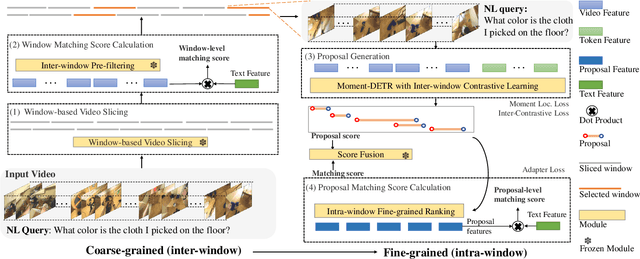
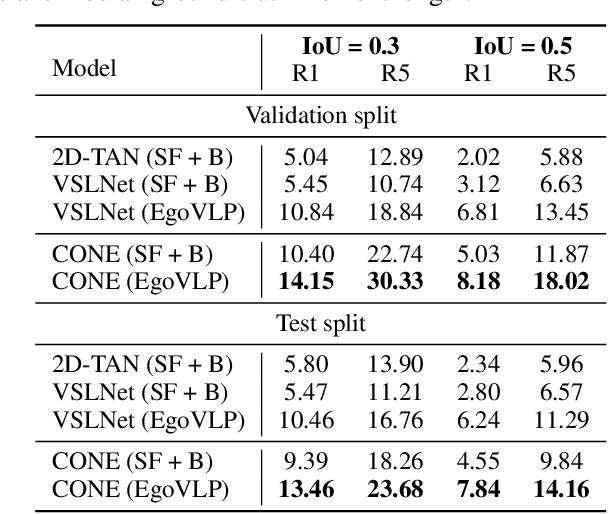
Video temporal grounding (VTG) targets to localize temporal moments in an untrimmed video according to a natural language (NL) description. Since real-world applications provide a never-ending video stream, it raises demands for temporal grounding for long-form videos, which leads to two major challenges: (1) the long video length makes it difficult to process the entire video without decreasing sample rate and leads to high computational burden; (2) the accurate multi-modal alignment is more challenging as the number of moment candidates increases. To address these challenges, we propose CONE, an efficient window-centric COarse-to-fiNE alignment framework, which flexibly handles long-form video inputs with higher inference speed, and enhances the temporal grounding via our novel coarse-to-fine multi-modal alignment framework. Specifically, we dynamically slice the long video into candidate windows via a sliding window approach. Centering at windows, CONE (1) learns the inter-window (coarse-grained) semantic variance through contrastive learning and speeds up inference by pre-filtering the candidate windows relevant to the NL query, and (2) conducts intra-window (fine-grained) candidate moments ranking utilizing the powerful multi-modal alignment ability of a contrastive vision-text pre-trained model. Extensive experiments on two large-scale VTG benchmarks for long videos consistently show a substantial performance gain (from 3.13% to 6.87% on MAD and from 10.46% to 13.46% on Ego4d-NLQ) and CONE achieves the SOTA results on both datasets. Analysis reveals the effectiveness of components and higher efficiency in long video grounding as our system improves the inference speed by 2x on Ego4d-NLQ and 15x on MAD while keeping the SOTA performance of CONE.
(Un)likelihood Training for Interpretable Embedding
Jul 01, 2022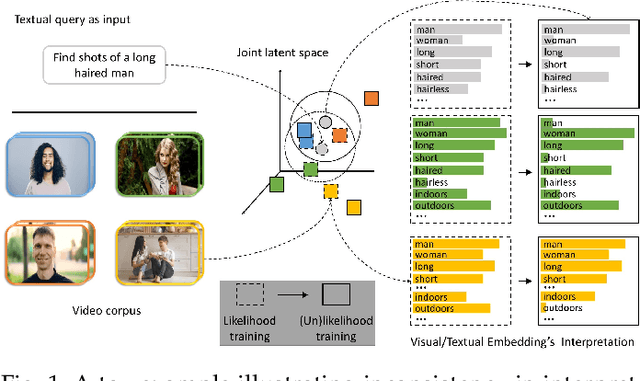
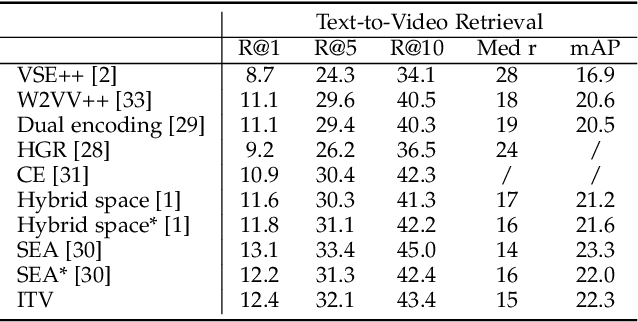
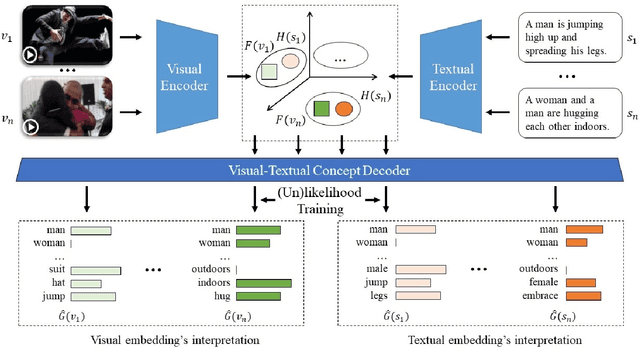
Cross-modal representation learning has become a new normal for bridging the semantic gap between text and visual data. Learning modality agnostic representations in a continuous latent space, however, is often treated as a black-box data-driven training process. It is well-known that the effectiveness of representation learning depends heavily on the quality and scale of training data. For video representation learning, having a complete set of labels that annotate the full spectrum of video content for training is highly difficult if not impossible. These issues, black-box training and dataset bias, make representation learning practically challenging to be deployed for video understanding due to unexplainable and unpredictable results. In this paper, we propose two novel training objectives, likelihood and unlikelihood functions, to unroll semantics behind embeddings while addressing the label sparsity problem in training. The likelihood training aims to interpret semantics of embeddings beyond training labels, while the unlikelihood training leverages prior knowledge for regularization to ensure semantically coherent interpretation. With both training objectives, a new encoder-decoder network, which learns interpretable cross-modal representation, is proposed for ad-hoc video search. Extensive experiments on TRECVid and MSR-VTT datasets show the proposed network outperforms several state-of-the-art retrieval models with a statistically significant performance margin.
Cross-lingual Adaptation for Recipe Retrieval with Mixup
May 08, 2022

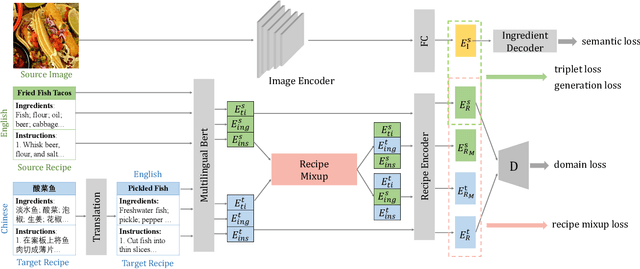
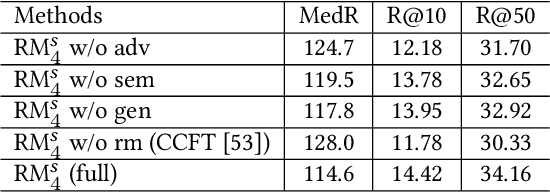
Cross-modal recipe retrieval has attracted research attention in recent years, thanks to the availability of large-scale paired data for training. Nevertheless, obtaining adequate recipe-image pairs covering the majority of cuisines for supervised learning is difficult if not impossible. By transferring knowledge learnt from a data-rich cuisine to a data-scarce cuisine, domain adaptation sheds light on this practical problem. Nevertheless, existing works assume recipes in source and target domains are mostly originated from the same cuisine and written in the same language. This paper studies unsupervised domain adaptation for image-to-recipe retrieval, where recipes in source and target domains are in different languages. Moreover, only recipes are available for training in the target domain. A novel recipe mixup method is proposed to learn transferable embedding features between the two domains. Specifically, recipe mixup produces mixed recipes to form an intermediate domain by discretely exchanging the section(s) between source and target recipes. To bridge the domain gap, recipe mixup loss is proposed to enforce the intermediate domain to locate in the shortest geodesic path between source and target domains in the recipe embedding space. By using Recipe 1M dataset as source domain (English) and Vireo-FoodTransfer dataset as target domain (Chinese), empirical experiments verify the effectiveness of recipe mixup for cross-lingual adaptation in the context of image-to-recipe retrieval.