 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCONE: An Efficient COarse-to-fiNE Alignment Framework for Long Video Temporal Grounding
Paper and Code


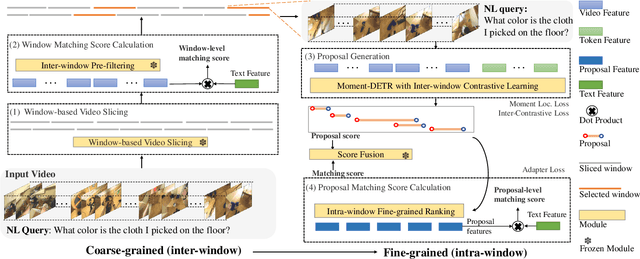
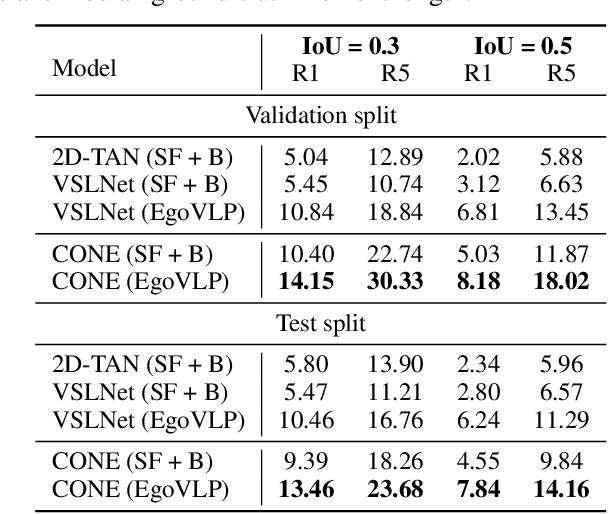
Video temporal grounding (VTG) targets to localize temporal moments in an untrimmed video according to a natural language (NL) description. Since real-world applications provide a never-ending video stream, it raises demands for temporal grounding for long-form videos, which leads to two major challenges: (1) the long video length makes it difficult to process the entire video without decreasing sample rate and leads to high computational burden; (2) the accurate multi-modal alignment is more challenging as the number of moment candidates increases. To address these challenges, we propose CONE, an efficient window-centric COarse-to-fiNE alignment framework, which flexibly handles long-form video inputs with higher inference speed, and enhances the temporal grounding via our novel coarse-to-fine multi-modal alignment framework. Specifically, we dynamically slice the long video into candidate windows via a sliding window approach. Centering at windows, CONE (1) learns the inter-window (coarse-grained) semantic variance through contrastive learning and speeds up inference by pre-filtering the candidate windows relevant to the NL query, and (2) conducts intra-window (fine-grained) candidate moments ranking utilizing the powerful multi-modal alignment ability of a contrastive vision-text pre-trained model. Extensive experiments on two large-scale VTG benchmarks for long videos consistently show a substantial performance gain (from 3.13% to 6.87% on MAD and from 10.46% to 13.46% on Ego4d-NLQ) and CONE achieves the SOTA results on both datasets. Analysis reveals the effectiveness of components and higher efficiency in long video grounding as our system improves the inference speed by 2x on Ego4d-NLQ and 15x on MAD while keeping the SOTA performance of CONE.