 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-lingual Adaptation for Recipe Retrieval with Mixup
Paper and Code


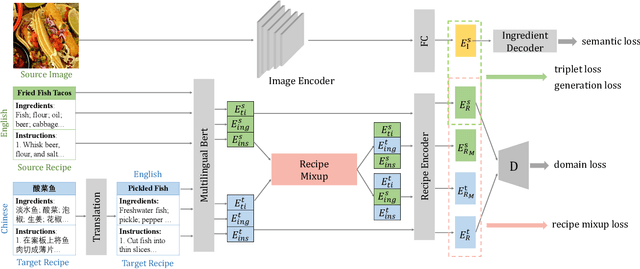
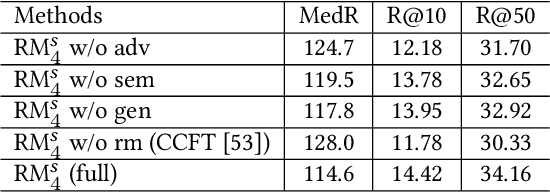
Cross-modal recipe retrieval has attracted research attention in recent years, thanks to the availability of large-scale paired data for training. Nevertheless, obtaining adequate recipe-image pairs covering the majority of cuisines for supervised learning is difficult if not impossible. By transferring knowledge learnt from a data-rich cuisine to a data-scarce cuisine, domain adaptation sheds light on this practical problem. Nevertheless, existing works assume recipes in source and target domains are mostly originated from the same cuisine and written in the same language. This paper studies unsupervised domain adaptation for image-to-recipe retrieval, where recipes in source and target domains are in different languages. Moreover, only recipes are available for training in the target domain. A novel recipe mixup method is proposed to learn transferable embedding features between the two domains. Specifically, recipe mixup produces mixed recipes to form an intermediate domain by discretely exchanging the section(s) between source and target recipes. To bridge the domain gap, recipe mixup loss is proposed to enforce the intermediate domain to locate in the shortest geodesic path between source and target domains in the recipe embedding space. By using Recipe 1M dataset as source domain (English) and Vireo-FoodTransfer dataset as target domain (Chinese), empirical experiments verify the effectiveness of recipe mixup for cross-lingual adaptation in the context of image-to-recipe retrieval.