 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGroundNLQ @ Ego4D Natural Language Queries Challenge 2023
Paper and Code
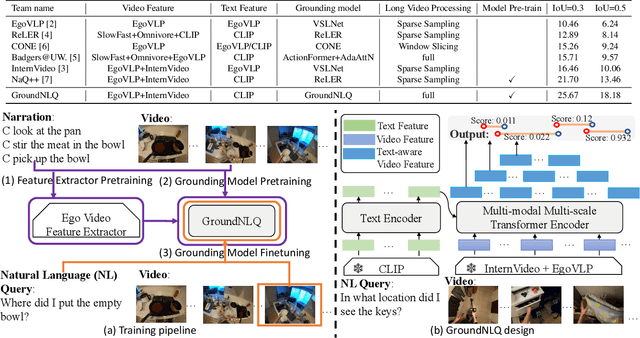
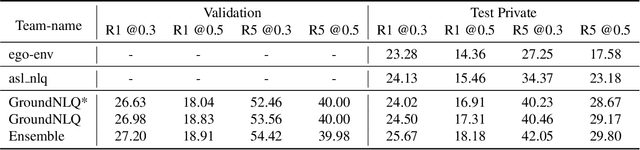

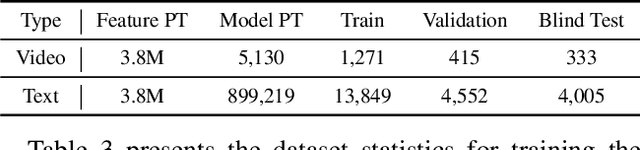
In this report, we present our champion solution for Ego4D Natural Language Queries (NLQ) Challenge in CVPR 2023. Essentially, to accurately ground in a video, an effective egocentric feature extractor and a powerful grounding model are required. Motivated by this, we leverage a two-stage pre-training strategy to train egocentric feature extractors and the grounding model on video narrations, and further fine-tune the model on annotated data. In addition, we introduce a novel grounding model GroundNLQ, which employs a multi-modal multi-scale grounding module for effective video and text fusion and various temporal intervals, especially for long videos. On the blind test set, GroundNLQ achieves 25.67 and 18.18 for R1@IoU=0.3 and R1@IoU=0.5, respectively, and surpasses all other teams by a noticeable margin. Our code will be released at\url{https://github.com/houzhijian/GroundNLQ}.