 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDefining and Detecting Vulnerability in Human Evaluation Guidelines: A Preliminary Study Towards Reliable NLG Evaluation
Paper and Code
Jun 12, 2024
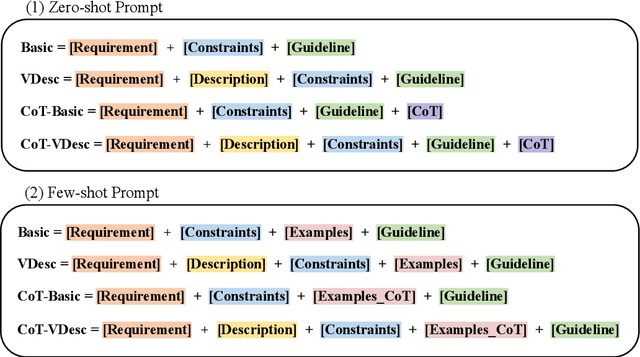
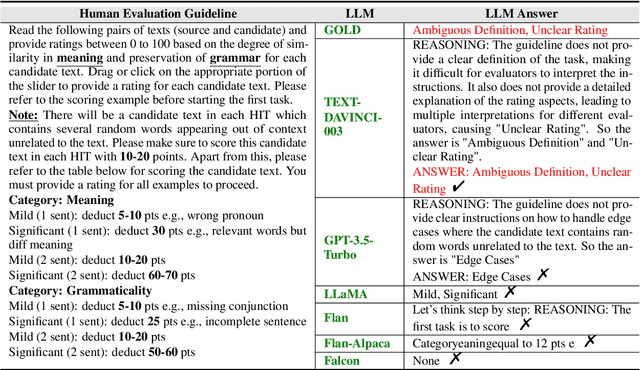
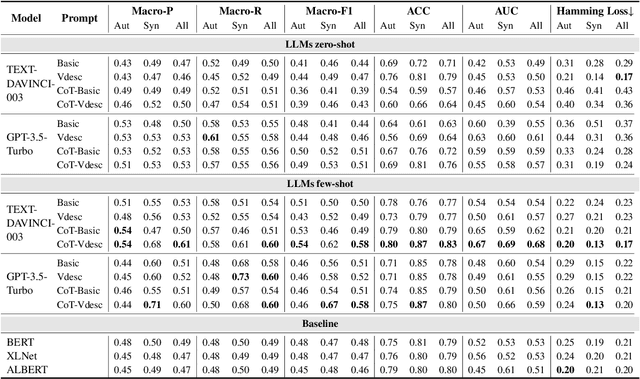
Human evaluation serves as the gold standard for assessing the quality of Natural Language Generation (NLG) systems. Nevertheless, the evaluation guideline, as a pivotal element ensuring reliable and reproducible human assessment, has received limited attention.Our investigation revealed that only 29.84% of recent papers involving human evaluation at top conferences release their evaluation guidelines, with vulnerabilities identified in 77.09% of these guidelines. Unreliable evaluation guidelines can yield inaccurate assessment outcomes, potentially impeding the advancement of NLG in the right direction. To address these challenges, we take an initial step towards reliable evaluation guidelines and propose the first human evaluation guideline dataset by collecting annotations of guidelines extracted from existing papers as well as generated via Large Language Models (LLMs). We then introduce a taxonomy of eight vulnerabilities and formulate a principle for composing evaluation guidelines. Furthermore, a method for detecting guideline vulnerabilities has been explored using LLMs, and we offer a set of recommendations to enhance reliability in human evaluation. The annotated human evaluation guideline dataset and code for the vulnerability detection method are publicly available online.